|
31 de diciembre del 2001 Vol.2 No.4
|
Técnicas de Predicción y Convergencia para Determinar el Estado
Global de Mundos Virtuales Distribuidos Multiusuario
Leandro Balladares Ocaña.
Servando
Islas Ortega.
Palabras Clave
:
Sistemas Distribuidos, Realidad Virtual Distribuida, Mundos Virtuales Distribuidos Multiusuario, Técnicas de Predicción (Dead Reckoning) y
Convergencia, Videojuegos Multiusuario.,
.
Uno de los principales problemas al implantar aplicaciones de
mundos virtuales distribuidos multiusuario (MV), es el tiempo que se emplea en
la generación y actualización de imágenes del mundo virtual en cada una de
las computadoras de los usuarios participantes, para proporcionarles la
ilusión de que todos están viendo los mismos objetos y que están
interactuando los unos a los otros dentro de un único espacio. Por lo general,
este tiempo es demasiado en este tipo de aplicaciones, debido principalmente a
la cantidad de información que debe viajar por la red y todo lo que ello
implica (latencias altas). Sin embargo, las técnicas de predicción y
convergencia permiten aligerar este problema. En este artículo se describen
las técnicas de predicción y convergencia, comúnmente utilizadas para
determinar el estado global (EG) de MV, así como las ventajas y desventajas de
su uso en el desarrollo de aplicaciones de MV.
[English]
Una de las metas fundamentales de un Mundo Virtual Distribuido
Multiusuario (MV) es proporcionar a los usuarios participantes la ilusión de
que todos están viendo los mismos objetos y que están interactuando los unos
a los otros dentro de un único espacio virtual, todo ello en tiempo real. Por
ejemplo, los usuarios desean conocer la ubicación de los demás participantes
dentro del mundo, de tal manera que puedan tomar acciones con base en ello
(saludarlos, alejarse de ellos, etcétera). Por ejemplo, si la aplicación del
MV es un videojuego, cada uno de los jugadores debe ver a sus adversarios en la
ubicación que ocupan para dispararles, huir, etcétera. Cuando un jugador
dispara su arma, los demás competidores necesitan saber la posición actual de
los disparos para evadirlos.
Uno de los principales problemas en el desarrollo de MV es
cómo asegurarse que los usuarios participantes mantienen una vista consistente
del estado global (EG), el cuál es dinámico y se encuentra distribuido. El EG
es la información que cambia en el tiempo y que cada una de las computadoras
participantes (hosts) debe conocer sobre el mundo virtual. El estado dinámico
en un MV constituye información sobre quién y en qué está participando
actualmente, la ubicación relativa de los participantes, su comportamiento
actual, etcétera.
A continuación se describe una de las técnicas más
conocidas y comúnmente utilizadas en el desarrollo de MV, para determinar el
estado global del mundo virtual. Esta técnica es conocida como dead-reckoning
o predicción, en español. Como su nombre lo indica, esta técnica busca
predecir el estado de las entidades participantes en un MV, de tal manera que
la cantidad de información a transmitir por la red sea mínima y que la
latencia de actualización de la pantalla sea lo más rápido posible.
Asimismo, se describen algunas técnicas de convergencia, utilizadas en
conjunción con los algoritmos de estimación, para suavizar el desplazamiento
de los objetos que se encuentren en movimiento.
Estimación del Estado Global de un MV Mediante Técnicas de
Estimación
La idea de las técnicas de estimación consiste en transmitir
paquetes de actualización de estado a las máquinas participantes en el MV, a
frecuencias bajas, y usar esta información para aproximar el EG verdadero; es
decir, entre cada paquete de actualización, cada máquina participante (host)
predice la posición, velocidad, aceleración y otros estados de las entidades
del MV, basándose en la información almacenada localmente. Este tipo de
técnicas se utiliza en aplicaciones de MV, en las que se desea generar 30
cuadros o imágenes por segundo (mínimo requerido para animación en tiempo
real), pero únicamente se reciben paquetes de actualización una vez por
segundo.
En la figura 1, por ejemplo, en el tiempo 3 una entidad está
localizada en la posición (4,5) y viaja a una velocidad de (3,2). En el tiempo
3.5, se puede estimar que la entidad estará localizada en (5.5,6). Desde
luego, la entidad puede no estar realmente en tal posición en dicho tiempo
(por ejemplo si acelera en una dirección distinta), pero hasta que no se
reciba más información sobre la verdadera posición, se usará la
información de la posición estimada.

Figura 1. Predicción del estado actual de una entidad remota.
Este tipo de técnicas de predicción se conocen como protocolos
de estimación. Éstos sacrifican la exactitud de estado global, pero permiten
reducir el tráfico de mensajes por la red y con ello soportar un número mayor
de participantes en una sesión del MV. Un protocolo de estimación consiste en
dos elementos: una técnica de predicción y una técnica de convergencia. La
técnica de predicción es la forma como se calculan los estados actuales de
las entidades, basándose en información recibida previamente. Por ejemplo, en
el caso anterior, el algoritmo de predicción estimó que la entidad estaría
en la posición (5.5,6) en el tiempo 3.5 y en la posición (7,7) en el tiempo 4
(ver figura 2).
La predicción es sólo un estimado de la verdadera posición de
la entidad. Supóngase, por ejemplo, que se recibe un nuevo paquete de
actualización en el tiempo 4, mostrando que la entidad está localizada
actualmente en la posición (6,2) y viajando a una velocidad de (3,1). De
acuerdo con esto, la posición desplegada actualmente (7,7) es incorrecta.
Además, las predicciones para las futuras posiciones de la entidad, cambiarán
debido a la nueva información de velocidad. Además, la entidad se debe mover
de su posición calculada y trayectoria predicha previamente, a su posición
revisada y trayectoria predicha actualmente. La técnica de convergencia define
cómo se debe corregir la posición y trayectoria de la entidad. Por ejemplo,
puede moverse la entidad a la posición (8,9) y subsecuentemente seguir la
nueva ruta predicha. Sin embargo, este salto a la nueva posición genera un
efecto, que repercute negativamente en la animación de las entidades remotas,
siendo esto molesto para el usuario. Por ello debe corregirse gradualmente la
posición desplegada de la entidad en los siguientes cuadros de animación,
hasta que ésta coincida con la nueva trayectoria predicha.
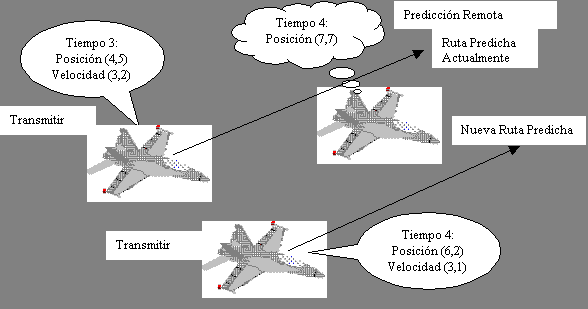
Figura 2. La convergencia es usada para corregir imprecisiones en la posición predicha (y desplegada) y mover suavemente el objeto hacia su nueva ruta.
Predicción Usando Polinomios Derivados
Los protocolos de estimación más comunes usan polinomios
derivados para predecir la posición futura de una entidad. Un polinomio
derivado se forma construyendo una fórmula que involucre varias derivadas de
la posición actual de la entidad. Como es sabido, la primera derivada de la
posición es la velocidad y la segunda derivada, la aceleración. Pueden usarse
este tipo de valores para estimar la posición de los objetos.
El polinomio derivado más simple es un polinomio de orden
cero, el cual usa la posición instantánea del objeto, pero no emplea ninguna
información derivada. La información predicha es de la siguiente
manera:
posición predicha después de t segundos =
posición
Los polinomios de orden cero simplemente copian el estado del
paquete de actualización en el cahe del estado local del host. Los polinomios
de este tipo no son muy usados, debido a que son una forma degenerada de
predicción.
El primer polinomio derivado, no degenerado, tiene orden uno.
Esto significa que éste toma ventaja de la primera derivada de la posición,
llamada velocidad. Debido a que la velocidad da alguna indicación sobre el
comportamiento del objeto en el tiempo, la predicción de primer orden es una
mejora significante sobre el caso de orden cero. La formula de cálculo de la
distancia, da la predicción de la posición:
posición predicha después de t segundos = posición +
velocidad x tiempo
El paquete de actualización de estado debe proporcionar la
posición actual del objeto y la velocidad instantánea. Este es el polinomio
usado en los ejemplos anteriores. Algunos de los primeros juegos multijugador
en red, tal como Amaze, Berglund (1985), desarrollado en la Universidad de
Stanford, usaron predicción con polinomios de primer orden.
Puede obtenerse una mejor predicción de la posición,
incorporando más derivados en el paquete de actualización. Los polinomios de
segundo orden incluyen la aceleración del objeto:
posición predicha después de t segundos = posición +
velocidad x tiempo x aceleración x
tiempo
El paquete de actualización de estado debe proporcionar la
posición, velocidad y aceleración del objeto. La predicción con polinomios
de segundo orden, es la técnica de predicción más popular en los videojuegos
y MV de la actualidad. Esta técnica es fácil de entender y programar, rápida
de calcular, y proporciona predicciones relativamente buenas de las posiciones
de los objetos. Por ejemplo, la predicción de segundo orden es la piedra
angular del protocolo DIS (Distributed Interactive Simulation), estándar 1278
de la IEEE, el cual es usado ampliamente en aplicaciones de MV con fine
bélicos IEEE (1995).
Predicción con Polinomios Híbridos
Como se verá enseguida, no es necesario que la elección del
orden de los polinomios derivados sea absoluta. Por ejemplo, cuando se recibe
un paquete de actualización, la máquina remota puede elegir dinámicamente
entre un polinomio de predicción de primer o segundo orden. ¿Cuál es la
ventaja de esto? Los polinomios de primer orden requieren de menos operaciones.
Por lo tanto ofrecen un mejor desempeño cuando la entidad tiene una
aceleración mínima. Por otro lado, hay ocasiones en que la posición del
objeto puede ser predicha con más exactitud, ignorando la aceleración. Por
ejemplo, cuando la aceleración del objeto cambia frecuentemente es mejor
ignorarla, ya que considerarla puede producir una estimación errónea, debido
a un cambio de aceleración que ocurra antes de que se reciba el siguiente
paquete de actualización.
El protocolo de estimación basado en la historia de la
posición (Position History-Based Dead Reckoning-PHBDR), desarrollado por
Singhal y Cheriton para el sistema PARADISE de Stanford, es un ejemplo de una
propuesta híbrida que dinámicamente elige entre polinomios derivados de
primer y segundo orden, Singhal (1996). Cuando un paquete llega, el protocolo
evalúa el movimiento del objeto, con base en tres de las actualizaciones más
recientes. Si ha habido una aceleración mínima o si la aceleración ha sido
substancial, entonces el protocolo selecciona un polinomio derivado de primer
orden. Deben proporcionarse valores de tolerancia para cada entidad, los cuales
son usados para definir, tanto la aceleración mínima, como la substancial. El
comportamiento de la aceleración es usado para seleccionar un algoritmo de
convergencia apropiado.
El protocolo PHBDR se basa en la propuesta no tradicional de
ignorar completamente información derivada instantánea. Los paquetes de
actualización contienen únicamente la posición más reciente del objeto. Las
máquinas remotas estiman la velocidad y la aceleración instantáneas,
promediando las muestras de posición proporcionadas por los paquetes de
actualización recibidos más recientemente. Esta propuesta tiene la ventaja de
eliminar dos terceras partes del ancho de banda requerido, debido a que evita
la transmisión de datos derivados. Además, tiene el efecto contraintuitivo de
mejorar en muchos casos la exactitud de la predicción. Como se verá, las
muestras de aceleración y velocidad instantáneas, pueden ser inexactas o
engañosas. El uso de promedios de velocidad y aceleración, permite al PHBDR
producir predicciones basadas en información más estable a largo
plazo.
Limitaciones de los Polinomios Derivados
Hasta este punto, se han considerado polinomios derivados de
orden cero, uno y dos, así como técnicas híbridas. Podría considerarse la
posibilidad de agregar más términos al polinomio, con el fin de mejorar la
predicción; sin embargo, se ha demostrado que la inclusión de más términos
raramente mejoran la calidad de la predicción de la posición. En muchos
casos, más términos únicamente empeoran las cosas. Además, entre más
términos se agreguen al polinomio, se debe transmitir una mayor cantidad de
información en cada paquete de actualización, lo que aumenta los
requerimientos de ancho de banda, en oposición a la razón por la que se ha
optado por el uso de algoritmos de predicción (reducción de la cantidad de
datos a transmitir).
A manera de conclusión, se puede decir que debido a que la
información derivada de orden superior es difícil de capturar e
inherentemente inexacta, y a que estos valores inexactos pueden impactar
negativamente la calidad del modelado del estado remoto, los derivados de este
tipo deben evitarse cuando se diseña un sistema de estimación para un MV [5].
Esta exploración de polinomios derivados ilustra la Ley de Retorno Disminuido
(Law of Diminishing Returns), que enuncia: "un esfuerzo mayor típicamente
proporciona progresivamente menos impacto en la efectividad total de una
técnica".
Algoritmos de Convergencia
Las técnicas de convergencia dicen qué hacer cuando se recibe
información actualizada para corregir una predicción inexacta. Un buen
algoritmo de convergencia permite corregir el estado predicho rápidamente, sin
crear efectos notables de distorsión visual para el usuario. La forma más
simple de convergencia es de orden cero, o convergencia rápida. La idea
detrás de esta técnica es corregir de inmediato la predicción, sin
preocuparse por los efectos visuales. Por ejemplo, supóngase que en el tiempo
4.5 se cree que la posición actual es (8.5,8). Ahora se recibe un paquete de
actualización, proporcionando información sobre el estado en el tiempo 4. Con
base en esta nueva información, se predice que la posición en el tiempo 4.5.
podría realmente ser (7.5,2.5). Usando un algoritmo de convergencia rápida,
simplemente se mueve la entidad a su nueva posición: (7.5,2.5), saltando desde
la posición desplegada actualmente: (8.5,8).
No obstante que la convergencia rápida es simple para entender
e implantar, ésta no proporciona el mejor despliegue visual. Una mejor
propuesta comprende una convergencia más lenta a la predicción nueva. Por
ejemplo, con convergencia linear se elige un punto de convergencia futuro, a lo
largo de la nueva ruta predicha. La entidad es desplegada como si viajara en
una línea recta, entre su posición desplegada actualmente y la ruta de
convergencia. La figura 3 muestra un ejemplo de convergencia linear, el cual es
similar al de la figura 2, con la adición de latencia de red. Supóngase que
la nueva localización predicha en el tiempo 5 es (9,3). Durante el periodo 4.5
a 5, la entidad podría moverse en línea recta, desde su posición desplegada
actualmente (8.5,8), al punto de convergencia (9,3). Después de alcanzar el
punto de convergencia, la entidad podría seguir la nueva ruta predicha hasta
que la predicción sea actualizada de nuevo. El intervalo entre el tiempo
actual y el punto de convergencia (de 4.5 a 5 en este ejemplo), se conoce como
periodo de convergencia.
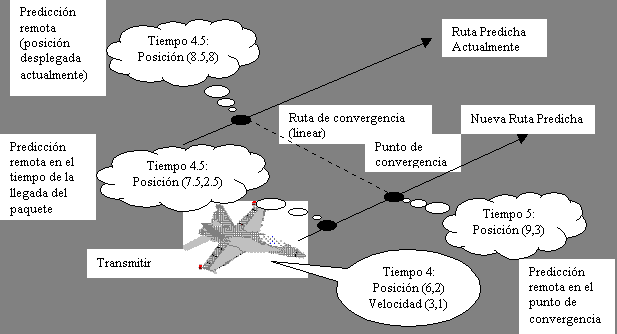
Figura 3. La selección de un punto de convergencia define un periodo de convergencia, entre la llegada del paquete de actualización y la finalización del proceso de convergencia.
La convergencia linear da continuidad a lo largo de la ruta
visual. Esto significa que el usuario no ve el salto de la entidad a la nueva
posición. Sin embargo, el movimiento no es necesariamente suave, debido a que
la entidad podría, al parecer, cambiar repentinamente en su dirección, como
si girara para seguir la ruta de convergencia y girara nuevamente para
continuar la nueva ruta predicha.
Aplicando técnicas de ajuste de curva más sofisticadas, puede
lograrse una mejor convergencia. Por ejemplo, como se muestra en la figura 4,
podría construirse una curva de orden cuatro, uniendo un punto un segundo
antes, a lo largo de la nueva ruta predicha, la posición predicha actualmente
y el punto de convergencia. Esto asegura que la entidad se moverá más
suavemente, desde el punto actual a la ruta de convergencia. Sin embargo, esta
propuesta todavía no genera un movimiento suave, cuando la entidad se mueve
desde la ruta de convergencia a la nueva ruta predicha en el punto de
convergencia. Para solucionar este problema, pueden usarse splines
cúbicos.
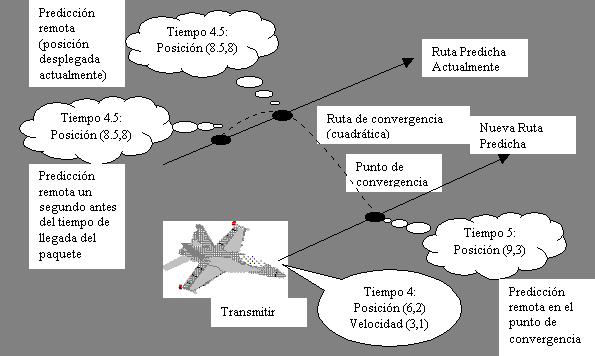
Figura 4. Las convergencia de orden cuatro proporciona una ruta de trasición más suave a la nueva ruta predicha.
La idea con los splines cúbicos es construir una curva de orden
tres, que conecte un punto un segundo antes a lo largo de la actual ruta
predicha, la posición actual desplegada, el punto de convergencia y un punto
un segundo después del punto de convergencia sobre la nueva ruta predicha.
Sacrificando la complejidad computacional de una ecuación de convergencia de
orden tres, se obtendrá una transición más suave sobre y fuera de la ruta de
convergencia.
Al igual que otros aspectos en el diseño de sistemas de
software en red, tales como videojuegos o MV, el algoritmo de convergencia
compensa la precisión visual contra la complejidad computacional. Los
algoritmos híbridos, tales como el PHBDR, intentan manejar dinámicamente esta
compensación, seleccionando entre algoritmos de convergencia linear y
cuadrática, y basándose en lo que parezca más adecuado en el tiempo actual.
Por ejemplo, si el error de predicción no es significante, PHBDR usa
convergencia linear para minimizar el gasto computacional, sobre la base de que
la convergencia cuadrática podría no proporcionar una mejora visual
significante.
Manejo de la Consistencia-Rendimiento de Procesamiento
Mediante la Transmisión no Regular de Paquetes de Actualización
Una vez que se introducen algoritmos de predicción conocidos en
las máquinas remotas, ya no se necesita ser tan rígido con respecto a cuándo
transmitirse las actualizaciones. Tomando ventaja del conocimiento sobre los
cálculos en las máquinas remotas, una máquina fuente puede reducir la
velocidad de transmisión de los paquetes de actualización
requeridos.
Considérese el siguiente ejemplo: sean dos personas A y B. A
tiene los ojos vendados y necesita viajar a través de un cuarto. La persona B
le dice a A qué dirección seguir y A sigue las instrucciones. A la persona B
le parece más razonable corregir la dirección de A, únicamente cuando éste
vaya por una dirección incorrecta, en lugar de corregirlo cada segundo. En
otras palabras, mientras A se mueva dentro de un margen de error, la persona B
la deja continuar su trayectoria actual sin ninguna
interferencia.
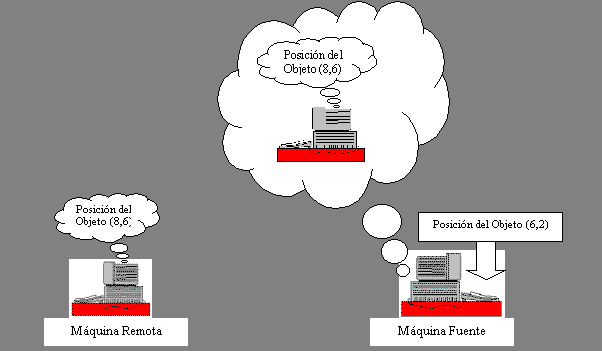
Figura 5. Mediante modelado del algoritmo de predicción, la máquina fuente puede evitar la transmisión de paquetes de actualización hasta que el error de la predicción remota exceda un margen.
El principio anterior puede ser aplicado para permitir, de
manera no regular, la transmisión de paquetes de actualización. La máquina
fuente puede modelar el algoritmo de predicción que está siendo usado por la
máquina remota, como lo muestra la figura 5. En lugar de transmitir
actualizaciones a intervalos regulares, la máquina fuente necesita propalarlas
cuando hay una divergencia significante (definida por un margen de error),
entre la posición actual del objeto y la posición predicha por la máquina
remota. Esta propuesta ha sido usada por una variedad de sistemas: el estándar
DIS para MVR, NPSNET (2001) y PARADISE (2001).
Esta técnica ofrece algunas ventajas a los MV. En primer lugar,
si el algoritmo de predicción es razonablemente exacto, entonces la
predicción de estado de la máquina fuente puede reducir de manera
significativa el envío de paquetes a través de la red. La máquina fuente no
transmite paquetes de actualización mientras la máquina remota mantenga una
vista razonablemente precisa del estado del objeto. En las otras propuestas,
por el otro lado, debía transmitirse un paquete de actualización a pesar de
la precisión del modelado remoto. En segundo lugar, la transmisión no regular
de actualizaciones permite garantizar precisión total de la información del
estado remoto. Mediante la transmisión de actualizaciones, cuando el estado
remoto exceda un margen de error, se asegura que dicho estado nunca llegará a
ser demasiado erróneo (con actualizaciones regulares, no se puede garantizar
la precisión de la predicción). En tercer lugar, las actualizaciones no
regulares permiten a la máquina fuente balancear dinámicamente sus recursos
de transmisión de red, basándose en la situación actual en el MV. Por
ejemplo, si el ancho de banda es limitado, la máquina fuente puede incrementar
temporalmente el margen de error sobre las entidades que residen dentro de
espacios abiertos amplios, y reducir simultáneamente el margen de error sobre
entidades remotas localizadas más cerca en el MVR. En resumen, esta técnica
proporciona una forma de adaptar dinámicamente el balance
consistencia-rendimiento de procesamiento, basándose en la consistencia de
cambios demandados en el MVR.
Si el algoritmo de predicción es realmente bueno o si la
entidad no se está moviendo de manera significativa, la máquina fuente
podría no transmitir nunca ningún paquete. Esto es indeseable, porque los
participantes nuevos nunca recibirán ningún estado inicial. Es además
indeseable porque los receptores no sabrán si la ausencia de actualizaciones
se debe a que el comportamiento del objeto no ha cambiado, o bien, a que la red
ha fallado o la entidad ha dejado el MVR.
Para solucionar los problemas anteriores, los sistemas que usan
la técnica, por lo general, colocan un tiempo de interrupción, como parte de
los datos del paquete de transmisión. De hecho, si la máquina fuente no ha
transmitido una actualización en un periodo de tiempo en particular, ésta
automáticamente genera uno. Los periodos de tiempo de interrupción son
relativamente grandes, al menos de 5 segundos. Con este tiempo, las máquinas
remotas pueden diferenciar entre fallas de otras máquinas o de red (indicado
por la no recepción de mensajes de la entidad por algún periodo de tiempo),
de las operaciones normales (indicado por recibir al menos, ocasionalmente,
paquetes de actualización de la entidad). Estas máquinas, además, pueden
tomar acciones apropiadas para alertar al usuario sobre cierta información que
puede ser incorrecta debido a estas fallas.
Las técnicas de estimación en máquinas remotas, reducen
típicamente los requerimientos de ancho de banda, porque los paquetes de
actualización pueden ser transmitidos a frecuencias más bajas que las
velocidades de generación de imágenes. Debido a que las máquinas reciben
actualizaciones sobre las entidades remotas, a velocidades más lentas que las
entidades locales (estos modelos son manejados por las entradas del usuario, en
lugar de los paquetes de entrada), los receptores deben usar predicción y
convergencia para integrar lo menos "arrugado" posible las entidades locales y
remotas en la pantalla. Cada máquina realiza su estimación en forma
independiente. Por lo tanto puede proporcionar una generación de imágenes
suave para el usuario local, basado en los paquetes periódicos de
actualización.
Por otro lado, la estimación introduce algunas limitaciones.
Primero: la estimación no garantiza que todas las máquinas comparten estados
idénticos sobre las entidades. En lugar de ello, los protocolos de estimación
requieren que las máquinas toleren y se adapten a posibles discrepancias.
Segundo: las simulaciones basadas en protocolos de estimación son usualmente
más complejas de desarrollar, mantener y evaluar. El desarrollador de la
aplicación debe ser consciente del comportamiento de la red, y adaptar
típicamente el software de simulación y los algoritmos, para operar dentro de
un ambiente de red de área amplia. Por ejemplo, debido a que la predicción de
la posición y la orientación de la entidad es imperfecta, la detección de
colisión requiere un protocolo de acuerdo distribuido. Para evitar la
presentación de una vista espasmódica de la posición de las entidades en la
pantalla, la máquina debe aplicar algún algoritmo de convergencia o suavidad,
para corregir el modelo extrapolado después de que un paquete nuevo de
actualización llegue. Tercero: los algoritmos de estimación deben ser
optimizados frecuentemente, basándose en el comportamiento de los objetos que
están siendo modelados. Es posible obtener un buen desempeño, en la mayoría
de los casos, con protocolos adaptados tales como PHBDR, pero el modelado
remoto altamente preciso depende de la optimización.
En resumen, las técnicas de estimación son las más
apropiadas cuando el ancho de banda es limitado; hay ciclos de cómputo
disponibles, o el MV contiene muchos participantes. Son menos apropiadas cuando
la precisión y la consistencia son características vitales para el
MV.
Berglund, E., and D. Cheriton
(1985) . (May 1985.). Amaze: A multiplayer computer game. IEEE Software
2(1): 30-39,.
(Piscataway, NJ: IEEE Standards
Press, September 1995.). IEEE standard for distributed interactive
simulation-Application protocols.. Institute for Electrical and
Electronics Engineers (1995) IEEE Standard 1278.1-1995..
NPSNET (2001) [en línea]
http://www.npsnet.nps.navy.mil/npsnet.
PARADISE (2001) [en
línea]http://www.dsg.stanford.edu/paradise.html.
Sandeep Singhal and
Michael Zyda . Networked virtual environments, design and implementation..
. (1999) Addison Wesley: ACM Press.
Singhal, S. ((1996)
August.). Effective remote modeling in large-scale distributed simulation
and visualization environments.. Ph.D dissertation. Department of
Computer Science, Stanford University, Palo Alto.
Singhal, S, and D. Cheriton
(Spring 1995.) Exploiting position history for efficient remote
rendering in networked virtual reality. PRESENCE: Teleoperators and
Virtual Environments 4(2): 169-193.
|