| 30 de diciembre del 2002 Vol.3 No.4 |
Transacciones para Cómputo Móvil: presente y perspectiva futura
Mtro. Gama Moreno Luis Antonio.
Alvarado Mentado Matías.
Palabras Clave:
Transacciones, cómputo móvil, transacciones móviles, bases de datos
En este artículo se presentan algunos modelos de transacciones que soportan el cómputo móvil junto con los principales retos a resolver para robustecerlo. El cómputo móvil está en auge y se refleja en el uso cada vez más frecuente de dispositivos portátiles inalámbricos para acceso y transmisión de información, tales como teléfonos celulares, organizadores personales y ordenadores portátiles. El soporte lo proporcionan estaciones de servicio mediante redes inalámbricas. Los retos que presenta la movilidad permitida por tales dispositivos requiere la creación de nuevos modelos transaccionales flexibles, robustos y seguros para ambientes móviles. En este trabajo se introducen los conceptos básicos relativos a transacción y sus características. Se comentan los modelos de transacciones planas y distribuidas más comúnmente implementados por los manejadores de bases de datos. Asimismo, se presentan los modelos de transacciones para dispositivos móviles inalámbricos. Se comentan las problemáticas transaccionales a resolver, dada la movilidad permitida por estas tecnologías de información.
[English]
Introducción
Los avances en las tecnologías de redes inalámbricas y dispositivos portátiles para la transmisión de información, han generado el nuevo paradigma de cómputo móvil (CM). El CM es el conjunto de métodos, técnicas y herramientas para el procesamiento y la transmisión de información, mediante dispositivos portátiles inalámbricos: celulares, pda's, laptops, radio-localizadores y paging (buscapersonas), entre otros. Utilizando el CM, los usuarios pueden tener acceso a información cultural, científica, económica, etcétera, sin importar su localización física.
La infraestructura que soporta el CM, inalámbrico, permite a usuarios remotos y en movimiento acceder a información de manera cómoda y flexible. En el estado actual de la tecnología, las redes de telecomunicación alámbricas han suministrado servicios para la transmisión de voz, datos y multimedia. La principal limitación de este tipo de tecnologías de información, es que restringen la movilidad del usuario. El valor agregado del CM inalámbrico, es dotar al usuario del acceso y la transmisión de información sin limitaciones de movilidad. El reto del CM es proporcionar movilidad de manera robusta y confiable.
Actualmente las arquitecturas más típicas para el cómputo móvil, son:1. Las redes inalámbricas (RI) y2. Las redes celulares (RC)Una RI (Wireless LAN) es un sistema de comunicación de datos flexible, muy utilizado como alternativa a la LAN cableada o como una extensión de ésta. Se compone de un conjunto de dispositivos enlazados mediante ondas de radio o luz infrarroja, de tal manera que se facilita la operación, en movimiento, de computadoras portátiles, equipadas con tarjetas de red inalámbricas y dispositivos equipados con infrarrojos.
Una RI está limitada en rango y diseñada para ser utilizada en ambientes locales (típicamente, dentro de edificios), y sin soporte para movimientos a grandes distancias. Una RC transmite datos a través de ondas de radio. Está dividida en celdas y cada una de ellas es servida por uno o más radio transceptores (transmisor/receptor). Actualmente se están extendiendo para dar servicio a dispositivos, como asistentes personales, radios de dos vías y beepers.
Las diferencias importantes entre una RI y una RC radican en el rango de cobertura y el ancho de banda. Con respecto al rango de cobertura, una RI está diseñada para operar en espacios cortos: entre treinta y hasta cientos de metros. Sin embargo, los avances en las tecnologías de las telecomunicaciones prometen mayores rangos de cobertura. Por otro lado, las RCs, mediante los mecanismos de roaming, pueden extender la cobertura de sus dispositivos entre las ciudades de toda una región. Con respecto al ancho de banda, las RIs pueden enviar datos en un rango de hasta 11 Mbps, mientras que las RCs tienen una capacidad de 9.6 kbps (Walters, 2000). No obstante estas diferencias entre RI y RC, ambas presentan limitaciones comunes para el CM en el procesamiento de transacciones.
Por lo dicho antes, un aspecto fundamental para el desarrollo del cómputo móvil, es la superación de las debilidades en cuanto al manejo robusto de las transacciones que soportan el CM. Las operaciones de una transacción han de formar una unidad atómica que opere los datos de manera consistente, sin interferencias entre transacciones concurrentes (aislamiento) y de manera durable. Es necesario revisar los modelos clásicos que operan para transacciones secuenciales (planas) y aún los que funcionan para transacciones distribuidas, puesto que los dispositivos inalámbricos están sujetos a una mayor incidencia de desconexiones y, típicamente, las transacciones en CM son procesadas por diferentes estaciones de servicios que se relevan entre sí, dada la movilidad del usuario. Así, el CM plantea problemas fundamentales de:1. Fragilidad2. Carencia de estándares3. Seguridad4. Consistencia5.
Aislamiento relativo
Tales problemas en el funcionamiento computacional interno son de carácter transaccional, en tanto que son un conjunto de operaciones de lectura, escritura, validación o cancelación de datos.En este artículo se presenta la evolución de las transacciones. En la sección 1 se da la introducción al paradigma del CM. En la sección 2 se aborda el concepto de transacción, así como una definición formal y sus propiedades, mientras que en la sección 3 se presentan los modelos existentes actualmente para el procesamiento de transacciones.
En la sección 4 se introduce el concepto de transacción distribuida y el mecanismo de confirmación a dos faces (two-phase commit). En la Sección 5 se presenta el concepto de transacción móvil, sus características y escenarios. En la sección 6 se describen los problemas implicados en su manejo. En la sección 7 se realiza una discusión con respecto a posibles soluciones a los problemas presentados en la sección 6. Finalmente, en la sección 8 se presentan las conclusiones.
Transacciones
En esta sección se introducen los conceptos y las propiedades de las transacciones tradicionales. Se muestra una definición formal del concepto de transacción dada por Bertino (1998)..Propiedades ACIDUna transacción es una unidad de trabajo lógica, es decir, un conjunto de operaciones de lectura/escritura o validación/cancelación, vistas como una unidad indivisible.
Los sistemas de procesamiento de transacciones han sido pioneros en muchos de los conceptos de la computación distribuida y de tolerancia-a-fallas. Así, introdujeron las propiedades de atomicidad, consistencia, aislamiento y durabilidad (ACID) para transacciones (Bertino, 1998) (Date, 2001) (Gray, 1994), con el fin de garantizar la fiabilidad de los datos procesados por una transacción. La atomicidad asegura que todas las operaciones de una transacción conformen una unidad, es decir, se ejecuten todas las operaciones o ninguna. En la consistencia, una transacción transforma una base de datos de un estado consistente a otro. Cuando las transacciones son ejecutadas concurrentemente, el DBMS debe asegurar que la consistencia de la base de datos sea preservada, tal y como si cada transacción se ejecutara en forma individual.
La propiedad de aislamiento (isolation) requiere que cada transacción observe un estado consistente en la base de datos, incluso cuando existan otras transacciones ejecutándose concurrentemente sobre ésta. Esta característica protege a las transacciones de los efectos de las actualizaciones que realizan simultáneamente otras transacciones. En relación a durabilidad, cuando una transacción es confirmada, los datos asentados deben ser permanentes en la base de datos, aun cuando sucedan fallas en el sistema. Esto conlleva a que una vez que la transacción validó, los datos pueden ser modificados sólo bajo el contexto de otra transacción.
Definición
Una transacción Ti es un conjunto de operaciones sobre el que se define un orden parcial (Bertino, 1998):Ti ⊆L∪{ai, ci}, donde:11. L es el conjunto de operaciones {lecturai(q), escriturai(q), donde q es cualquier objeto}; 2. ai indica que la transacción no ha sido completada satisfactoriamente;3. ci indica que la transacción fue completada satisfactoriamente; a) ai∈ Ti sii ci∉ Ti;b) ci∈ Ti sii ai∉ Ti;c) si t= ai∨ t=ci, entonces∀ p∈ Ti, p< i t;si lecturai(q), escriturai(q) ∈Ti, entonces ya sea que: lecturai (q)<i escriturai (q)∨ escriturai (q)<i lecturai (q).
Modelos de Transacciones
Actualmente se han desarrollado esfuerzos para resolver ciertas limitaciones de los modelos clásicos de transacciones (Bertino, 1998). Las investigaciones han guiado a la definición de nuevos modelos que extienden las características del modelo tradicional de transacciones. Por ejemplo, las actualizaciones complejas están soportadas por savepoints (Bertino, 1998) o por transacciones anidadas (Gray, 1994); la actualización en masa (Bertino, 1998) mediante transacciones encadenadas (Gray, 1994), etcétera.
Transacciones Planas
Una transacción plana (TP) (Gray, 1994) es un bloque básico de operaciones en una aplicación; es decir, no existen partes lógicas de la transacción que puedan ser tratadas en forma individual, es decir, no se pueden deshacer las acciones hechas sólo por una parte de la transacción. Esto se debe a la propiedad de atomicidad. Tal característica es importante para los sistemas centralizados, pero no es útil para las arquitecturas distribuidas. Una desventaja de las TP es que no consideran la realización de validaciones o cancelaciones de pequeñas partes de la transacción, así como tampoco la validación de resultados en varios pasos.
Transacciones Planas con Savepoints
La propiedad de atomicidad de las TP puede ser una ventaja y una desventaja. Si algo sucede mal durante la ejecución de la transacción, la aplicación rehace todas las operaciones o las deshace para garantizar la atomicidad. Para transacciones cortas este enfoque es ideal, pero no para aquellas de larga duración.
El mecanismo de "Savepoints" permite ir guardando estados de la transacción que son válidos, para que, en caso de fallas, no tenga que abortar toda la transacción, sino sólo ciertos puntos (savepoints).Se establece un savepoint cuando se invoca la función save work. Con esto el sistema registra el estado actual del proceso de la transacción.
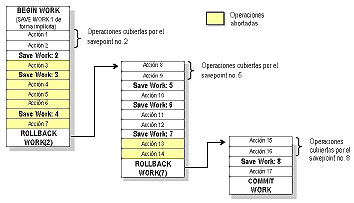
Figura 1
Esta función retorna un identificador que posteriormente puede ser utilizado para reestablecer el estado hasta dicho identificador, mediante la función rollback work. Así, en lugar de indicar que toda la transacción sea abortada, sólo se señala el punto hasta donde se han de deshacer los efectos realizados. La Figura 1 muestra la ejecución de una TP con savepoints. La Figura 2 muestra el estado final de la TP, después de haber desecho la acción 3, delimitada por el savepoint 2; las acciones 4, 5 y 6, delimitadas por el savepoint 3, y la acción 7, delimitada por el savepoint 4. Esta acciones fueron canceladas debido a la ejecución de rollback work(2). Las operaciones 13 y 14, delimitadas por el savepoint 7, son canceladas por la ejecución de rollback work(7).

Figura 2
Transacciones Encadenadas
Las transacciones encadenadas son una variación del esquema de transacciones planas con savepoints. Dadas las deficiencias de un ambiente de programación normal, este modelo intenta conseguir un compromiso entre la flexibilidad de un rollback y la cantidad de trabajo que se pierde después de cualquier falla.La idea de las transacciones encadenadas (Gray, 1994) es que en lugar de obtener savepoints, la aplicación valida (commit) el trabajo que ha sido terminado, y por consiguiente descarta la posibilidad de realizar rollback; sin embargo, requiere mantenerse dentro de la transacción, junto con los objetos adquiridos durante el proceso previo al que fueron confirmados. A este efecto de realizar un commit, seguido del intento de continuar con el trabajo de la transacción, es conocido como chain work.
Es una combinación de commit work con bejín work en un solo comando. Nótese que no es lo mismo llamar a commit work e iniciar una nueva transacción, pues la combinación de ambos comandos mantiene el contexto ligado a la aplicación, mientras que un commit normal completa y termina el contexto de la aplicación. Con el encadenamiento de transacciones se puede confirmar (commit) una transacción; liberar todos los objetos que ya no sean necesarios, y pasar el contexto de una siguiente transacción, iniciada implícitamente. Nótese que la validación de una transacción y el inicio de la siguiente, están vistas como una operación atómica, a diferencia del caso de un rollback, donde de la transacción sólo la última porción de trabajo sin confirmar será cancelada.
La Figura 3 muestra la representación gráfica de este modelo. Transacciones AnidadasEl modelo de transacciones anidadas (TA) fue introducido por Moss (Moss, 1985). En este modelo una transacción puede contener cierto número de subtransacciones, y cada sub-transacción, a su vez, puede contener subsubtransacciones. La transacción completa forma un árbol de transacciones, donde la transacción de mayor nivel en el tope del árbol, es llamada transacción raíz.
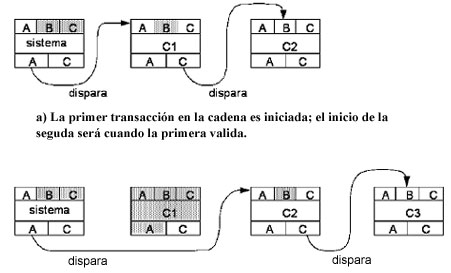
Figura 3
Las TA son una generalización de los savepoints: mientras que los savepoints organizan una transacción en secuencias de acciones que pueden ser canceladas individualmente, las transacciones anidadas forman una jerarquía de piezas de trabajo, realizado por subtransacciones, que pueden validar o abandonar, sin que toda la transacción tenga que ser cancelada. Una TA es un árbol de transacciones de profundidad arbitraria, donde los componentes son subtransacciones que ejecutan partes del trabajo. Cada subtransacción es en sí una transacción plana. Las transacciones que tienen subtransacciones son llamadas padres, mientras que sus transacciones se denominan hijas. Las transacciones que no poseen subtransacciones son hojas del árbol (Chen, 1994) (Doucet, 2000). La Figura 4 muestra el modelo de TA.
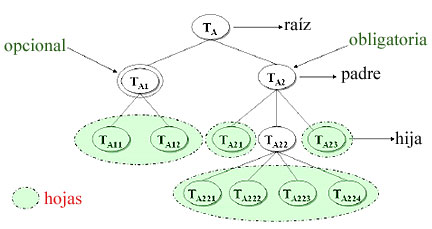
Figura 4
Transacciones Anidadas Abiertas
En el modelo de transacciones anidadas abiertas (TAA), al igual que las transacciones anidadas, una transacción puede tener varias subtransacciones, las cuales a su vez pueden contener varias subsubtransacciones, formando así un árbol de transacciones. Las transacciones anidadas abiertas (Open Nested Transaction) están conformadas por una jerarquía de transacciones, sobre diferentes niveles de abstracción y un conjunto de relaciones de conmutatividad, que definen en cada nivel los conflictos entre operaciones predefinidas.
Su principal diferencia con las TA radica en que las subtransacciones pueden validar (esto significa que sus efectos son visibles a otras transacciones), independientemente de la validación de la transacción raíz. El abandono de las TAA se hace efectivo a través de operaciones inversas de alto nivel, que compensan las subtransacciones ya validadas (Pitoura, 1995). Otra diferencia con las transacciones anidadas (cerradas), es que las transacciones anidadas abiertas pueden contener subtransacciones cerradas, que no liberan resultados parciales, y subtransacciones abiertas, que sí liberan sus resultados parciales.
Transacciones Divididas
En este modelo (Split Transactions) (Chrysanthis, 1993), es posible que una transacción A se divida en dos transacciones B y C, donde B sea la transacción original. B y C pueden ser independientes y confirmar (commit) o abortar (abort) independientemente, o bien, pueden serializarse, es decir, suceder B y después C. La principal ventaja de este modelo es que es posible una mayor flexibilidad en el aislamiento de transacciones, permitiendo compartir datos entre las transacciones B y C, de tal forma que C pueda observar los efectos realizados por B.
Transacciones Anidadas-Divididas
Este modelo combina las características de los modelos de transacciones anidadas (Nested Transaction) y transacciones divididas (Split Transactions). Dada una transacción anidada, es posible dividir una de sus hojas, un nodo interno o el nodo raíz, y los nodos divididos pueden ejecutarse independientemente o serialmente.
Este modelo permite que los efectos de las subtransacciones puedan ser permanentes en la base de datos y no tengan que confirmar sus resultados como en las transacciones anidadas, lo que depende de sus ancestros. Las transacciones anidadas-divididas son un ejemplo del modelo de transacciones anidadas abiertas, donde los componentes de una transacción (subtransacciones) pueden decidir validar sus efectos en la base de datos (Chrysanthis, 1993).
Transacciones Distribuidas
Una transacción distribuida (TD) es típicamente una transacción plana que es ejecutada en un sistema distribuido y por tal motivo necesita visitar varios nodos en la red, dependiendo de donde se encuentren los datos.La estructura de una transacción distribuida depende de la distribución de los datos en la red; es decir, aun cuando se trata de una TP, desde el punto de vista de la aplicación, una transacción distribuida puede ser ejecutada si los datos se encuentran dispersos a través de varios nodos (Gray, 1994).
Supóngase que la transacción T es ejecutada en el nodo A, el cual requiere las tablas X y Y para ser unidas (join), pero sólo la tabla X es accesible localmente. La tabla Y debe tener acceso a través de la red y además se encuentra fragmentada: un fragmento residente en el nodo B y otro en el nodo C. Esto ocasiona que la transacción T se divida en las subtransacciones T1 y T2, ejecutándose en los nodos B y C, respectivamente. La estructura de invocación de una transacción distribuida es similar a la de una transacción anidada, aunque existen diferencias.
Obsérvese que la descomposición de una TD en subtransacciones no refleja una estructura jerárquica en las aplicaciones donde es ejecutada, sino que está inducida por la ubicación de los datos en la red. Consecuentemente, las subtransacciones no se encuentran ejecutándose a niveles bajos, como sucede en las TA. Estas son divididas y ejecutadas al mismo nivel (del tope o raíz de una TA). En otras palabras, una simple transacción plana (desde la perspectiva de la aplicación) puede ser ejecutada como una transacción distribuida si es ejecutada en un sistema de bases de datos distribuidas y los datos que se accedan se encuentran dispersos a través de múltiples nodos.
Si una subtransacción solicita una acción de commit work, esto implica una validación de la transacción completa, la cual fuerza a todas las subtransacciones a validar. Para controlar la validación de una transacción distribuida se emplea el protocolo de validación a dos fases (2PC: Two-Phase Commit) (Oracle, 1992) (Özsu 1999).Protocolo Two Phase CommitConsidere una transacción distribuida T cuya ejecución involucra a los sitios S1, S2, …, Sn. Suponga que el administrador de transacciones (AT) en el sitio S1 supervisa la ejecución de T (coordinador global). Antes de que el AT en S1 pueda enviar una operación Commit a T, debe estar seguro de que el administrador de datos (AD) y el planificador en cada sitio están listos para llevar a cabo el proceso de confirmación. De otra forma, T podría validar en algunos sitios y abortar en otros, obteniendo una terminación inconsistente.
El AT en el sitio S1 podrá realizar un Commit(T) en cada planificador y el AD de los sitios S1, S2, …, Sn sólo después de haber recibido el consentimiento de cada planificador y AD de todos los sitios. En esencia, este es el mecanismo del protocolo de confirmación a dos fases (Oracle, 1992) (Özsu, 1999), que se muestra en las figuras 5 y 6.A diferencia de una transacción en una base de datos centralizada, una transacción distribuida involucra datos en diferentes bases de datos. Por lo tanto, se debe coordinar la confirmación o aborto de los cambios en una transacción distribuida como una sola unidad. A esto se le conoce como confirmación atómica, es decir, la transacción entera se confirma o la transacción entera es abortada.
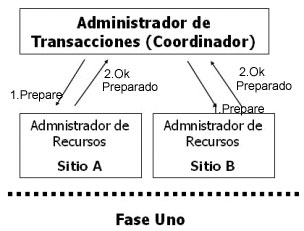
Figura 5
El funcionamiento del protocolo 2PC, asumiendo que no existan fallas, consta de las siguientes fases:1. Fase de preparación. El sitio inicial (donde inició la transacción distribuida), llamado coordinador global, solicita a todos los sitios participantes su voto para validar o abortar la transacción que corresponde a cada sitio. Aún si se presentan fallas, si cada sitio no se puede preparar, la transacción debe ser abortada. La Figura 5 muestra esta fase.2. Fase de confirmación. Si todos los participantes responden al coordinador que están preparados, entonces el coordinador solicita la confirmación en cada sitio de su respectiva transacción. La Figura 6 muestra esta fase.
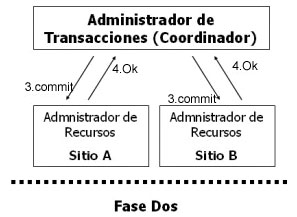
Figura 6
Transacciones Móviles
Los métodos tradicionales para el acceso a información están basados en el hecho de que la ubicación de un host en un sistema distribuido no cambia, y la comunicación entre hosts tampoco cambia durante una transacción. En un ambiente móvil, sin embargo, estas condiciones no se cumplen. La computación móvil se distingue del modelo clásico (computación fija), en:1. La movilidad de los usuarios nómadas y sus dispositivos, y 2. Las condiciones de los recursos móviles.
Las condiciones son tales, como anchos de banda muy bajos y vida limitada de las baterías. El constante cambio de un usuario móvil implica que se conectará de diferentes puntos de acceso, a través de enlaces inalámbricos. Durante el tiempo que permanezca conectado podría experimentar frecuentes interrupciones. Los enlaces inalámbricos son, aproximadamente, dos o tres veces más lentos que los enlaces fijos. Además, los hosts móviles dependen de la vida de sus baterías. Estas condiciones y limitaciones dejan mucho trabajo incompleto durante el proceso de una transacción.
Ambiente Móvil
La movilidad de un usuario de la computación móvil implica que se conectará desde diferentes puntos a través de enlaces inalámbricos y deberá permanecer conectado mientras está en movimiento, expuesto a posibles desconexiones. Los enlaces inalámbricos son relativamente inestables y son unas 2 ó 3 veces más lentos que los enlaces alámbricos. Además los hosts móviles dependen de las condiciones de vida de las baterías. Así, hay mucho trabajo previo para establecer un control completo.
Una red inalámbrica con clientes móviles es en esencia un sistema distribuido, pero existen características que distinguen a esta tecnología (Imielinski, 1993) (Ioannisdis, 1991) (Kumar, 1998):1. Asimetría en las comunicaciones2. Desconexiones frecuentes3. Fuentes de energía limitadas4. Tamaño del display5. Bajo ancho de banda6. Riesgos de seguridad7. Redes heterogéneas8. Cambios de dirección.
Arquitectura
En un ambiente de computación móvil, la red consiste en un conjunto de entidades: hosts móviles (HM) y hosts fijos (HF), como se muestra en la Figura 7. Algunos de los hosts fijos, llamados también Estaciones de Soporte Móvil (ESM), cuentan con una interfaz inalámbrica para comunicarse con los hosts móviles, que se encuentren localizados dentro de un radio de cobertura llamado célula o celda. Una célula es realmente un área de comunicaciones inalámbricas o una red local inalámbrica.
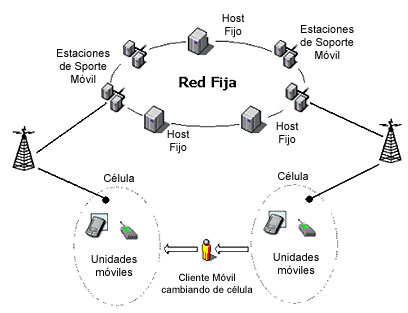
Figura 7
Un host móvil (HM) cambia constantemente su ubicación mientras se encuentra ejecutando procesos. Durante un proceso, el host móvil mantiene su conexión a la red a través de la ayuda de las ESM, las cuales ejecutan las transacciones y soportan el manejo de los datos. Cada ESM es responsable de todos los HM dentro de una pequeña área geográfica, conocida como celda o célula. Cuando un HM abandona una célula controlada por una ESM, se utiliza un protocolo hand-off (Dunham, 1999) (Imielinski, 1993) (Kayan, 1999) para transferir la responsabilidad de la transacción móvil y el soporte de los datos a la ESM de la nueva célula.
Características
Con el crecimiento de las tecnologías inalámbricas, se pueden tener accesos a los datos, sin importar la ubicación mediante el uso de transacciones móviles. Sin embargo, una transacción en este ambiente es diferente a las transacciones en los ambientes centralizados y distribuidos, debido a las siguientes características:1. La transacción móvil deberá dividir sus procesos en un conjunto de operaciones, algunas de ellas ejecutándose en hosts móviles y otras, en hosts fijos.2. Una transacción móvil comparte su estado y resultados parciales con otras transacciones, debido a la movilidad y las desconexiones.3. El proceso de las transacciones debe ser migrado a hosts fijos, mientras no se necesiten futuras intervenciones de usuarios.4. Las transacciones móviles requieren cálculos y comunicaciones que sean soportados por los hosts fijos.5.
Cuando un usuario móvil cambia de ubicación durante una transacción, la ejecución continúa en la nueva célula. La transacción ejecutada parcialmente debe ser continuada en el host fijo, acorde a las instrucciones dadas por el usuario móvil. Así, se requieren diferentes mecanismos si el usuario desea continuar su transacción en un nuevo destino.6. Conforme un host móvil cambia de una célula a otra, tanto el estado de la transacción, como el estado de los datos accesados y la ubicación de la información, también se mueven.7. Las transacciones móviles son de larga-duración, debido a la movilidad de los datos y los usuarios. También se debe a las frecuentes desconexiones.8. Las transacciones móviles soportan y manejan consistencia, recuperación, desconexión y mutua consistencia de los objetos replicados.
Hoy en día, para el soporte de transacciones móviles, los modelos de procesamiento de transacciones deben ajustarse a las limitaciones del CM, tales como comunicaciones poco fiables, fuentes de energía limitadas y poca capacidad de almacenamiento. Los cálculos móviles deben minimizarse debido a las desconexiones frecuentes. Las operaciones sobre datos compartidos deben ser coherentes en transacciones ejecutadas, tanto en los host móviles como en los fijos. El bloqueo de transacciones en ejecución, ya sea en el host móvil o en el fijo, debe minimizarse para reducir los costos de comunicación e incrementar la concurrencia. Un soporte apropiado para transacciones móviles debe proveer autonomía local para permitir que las transacciones sean procesadas y validadas en el host móvil, a pesar de desconexiones temporales.
En un sistema de procesamiento de transacciones distribuidas, una transacción Ti puede subdividirse en un número finito de sub-transacciones, donde cada una es una transacción, de tal forma que el conjunto de operaciones de cada transacción es un subconjunto de las operaciones de Ti y los órdenes parciales de cada sub-transacción son consistentes con Ti. Veremos a una transacción móvil como un conjunto de fragmentos, según la definición de Kumar y Dunham (Kumar, 1998).
Así, tenemos queTi = { ei1, ei2 ... ein }donde eij es un fragmento de ejecución. La siguiente es una definición formal de una transacción móvil:Un fragmento de ejecución eij es un orden parcial eij = {σ j ,≤ j}, donde:1. σj = OSj ∪{Nj} donde OSj = ∪k Ojk, Ojk ∈{ lectura, escritura }, y Nj∈ {abortL, commitL}. Aquí existe una dependencia de ubicación del commit y abort.2. Para cualquier Ojk y Ojl donde Ojk=R(x) y Ojl=W(x) para un objeto de datos x, entonces ya sea que Ojk≤ j Ojl ó Ojl ≤j Ojk.3. ∀Ojk ∈OSj , Ojk ≤j Nj.La única diferencia entre un fragmento de ejecución y una transacción, es que el commit o abort depende de la ubicación donde se presente, a diferencia del commit o abort tradicional. Cada fragmento está así asociado con su ubicación. Sin embargo, debemos mantener la idea de que si los datos que han sido actualizados son una réplica temporal, entonces los fragmentos actualizan todas las réplicas. De esta manera no está sujeto a las restricciones de la ubicación y asemeja a una transacción regular.
Una transacción móvil Ti, es una tri-upla<Fτ, Lτ, FLMτ>, donde:1. Fτ = { ei1, ei2 ... ein } es un conjunto de fragmentos de ejecución;2. Lτ = { li1, li2 ... lin } es un conjunto de ubicaciones, y 3. FLM τ= { flmi1, flmi2 ... flmin } es un conjunto de mapeos de fragmentos de ubicación, donde ∀j, flmij(eij) = lij.
Escenarios
Los siguientes escenarios ilustran los tipos de movilidad que se pueden presentar y que pueden impactar el procesamiento de una transacción. En algunos escenarios la movilidad es forzada por los datos o el movimiento de la transacción.1. Ti se origina en un HM (HM-H de Ti) y se completa su ejecución totalmente en ese mismo HM. El HM-H no se mueve durante la ejecución de Ti. Este es el caso en donde no existe movimiento de algún tipo (Figura 8a).2. Ti completa su ejecución totalmente en un HM. Cualquiera de los datos requeridos que no se encuentren en este HM serán movidos a ella, desde otros sitios (cualquier otro HM o ESM u otro nodo en la red fija. Figura 8b). Sin embargo, durante una ejecución, el HM se puede mover a una célula foránea. Haremos referencia a este tipo de ejecución como "atomicidad local".
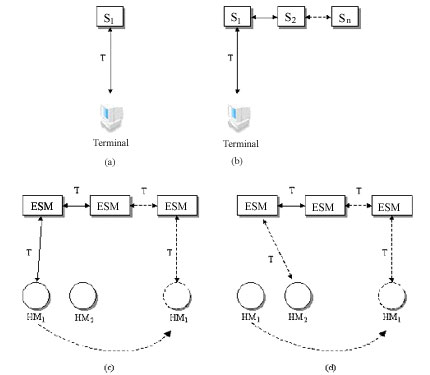
Figura 8
La atomicidad local es bastante común en la computación móvil. Los agentes de ventas, mientras viajan, normalmente querrán por eficiencia procesar localmente todas las porciones de una orden (fragmentos de ejecución) y minimizar la sobrecarga de mensajes de comunicación.3. Ti puede esperar a un número de HM foráneos durante el ciclo de vida de ejecución de Ti. Estos HM foráneos pueden estar ubicadas en diferentes células, incluyendo a la CH (Célula Home) de Ti. Esto se puede identificar como una migración de la transacción, la cual es una característica del procesamiento de transacciones distribuidas.
Algunas razones posibles de esta migración, son: la disponibilidad de los datos, el rendimiento de los procesadores, etcétera. En una plataforma móvil, un fragmento de ejecución puede ser movido desde HM1 hasta HM2, debido a que HM1 no está disponible para proveer los requerimientos de datos como tal o porque HM1 está sobrecargado.4. Un eij puede visitar sólo un subconjunto predefinido de HM. Este tipo de restricción para el movimiento de eij es usualmente dependiente del orden de distribución de la base de datos en los HM. Por ejemplo, Ti puede ser una transacción para la demanda de un seguro. La información necesaria podría estar localizada en un cierto número de HM. El manejo de la transacción Ti y sus fragmentos eij, sería más fácil si se conoce el patrón de movimientos (el conjunto de eij de un HM que serán visitados).

Problemas en las Transacciones Móviles como Efectos de la Movilidad
En esta sección se describen las propiedades que se ven afectadas por la movilidad y en qué formas. Esto permitirá identificar las características fundamentales que los modelos de transacciones deben incorporar.
En los Datos y su Manejo
A la forma de obtener datos, dependiendo de la ubicación geográfica donde se encuentren almacenados o dependiendo de la ubicación geográfica de los HM o ESM, donde la consulta fue originada, se le denomina "Datos dependiendo de su ubicación".

En la Consistencia
En los ambientes de cómputo distribuido y centralizado existe sólo un valor que es correcto para cada objeto de datos. El término consistencia mutua es utilizado para indicar que todos los valores (en un sistema distribuido con réplicas de los datos) convergen en el mismo valor correcto. Se dice que una base de datos replicada está en estado de consistencia mutua, si todas las reglas de integridad de la base de datos se cumplen. En CM este concepto se complica mucho, de la misma manera que la replicación de los datos.
Cuando se ejecutan consultas dependientes de su ubicación, se obtiene una vista consistente si todos los datos son manipulados con respecto a una misma ubicación, de tal forma que, por ejemplo, si obtenemos una lista de hoteles y restaurantes, éstos deberán pertenecer a una misma ubicación. No sería correcto obtener hoteles en Guadalajara y restaurantes en Cancún. A este concepto lo denominamos consistencia espacial. Hace referencia a la consistencia original como una consistencia temporal (Kumar, 1998).1.

Consistencia Temporal. Indica que todos los valores de los objetos de datos deben satisfacer un conjunto dado de reglas de integridad. Una base de datos se encuentra en un estado temporalmente consistente, si todas las réplicas temporales de un objeto tienen el mismo valor.2. Consistencia Espacial. Indica que todos los valores de los objetos de los datos (instancias de un esquema en común), para una replicación espacial, están asociadas con una y sólo una región de datos. Además, satisfacen las reglas de consistencia que han sido definidas para la región.
En la Atomicidad
El propósito de la atomicidad es preservar la consistencia de los datos. Sin embargo, en un ambiente móvil tenemos dos tipos de consistencia. Ciertamente, la atomicidad a nivel de los fragmentos se necesita para asegurar la consistencia espacial. Sin embargo, a nivel de transacción no hay atomicidad, debido a que tendremos algunos fragmentos ejecutándose y otros no.
Una transacción móvil Ti satisface la atomicidad espacial si cada fragmento de ejecución, eij, de Ti es atómico. Se dice que Ti es Espacialmente Atómico si cada fragmento de ejecución, eij, es atómico.
En la Independencia
La independencia en las transacciones asegura que una transacción no interfiera con la ejecución de otra transacción. La independencia es normalmente forzada por algunos mecanismos de control de concurrencia. Como en la atomicidad, la independencia es necesaria para preservar y asegurar la consistencia de los datos, de tal forma que se necesita revaluar la independencia cuando se busca la consistencia espacial. Al igual que para la consistencia, la independencia al nivel de transacción es muy estricta.
En la Validación de una Transacción
Cuando una transacción plana valida, hace que sean pertinentes las actualizaciones hechas a la base de datos. Esto sucede normalmente con una sola validación (commit) por cada Ti. Sin embargo, para asegurar tanto la consistencia, la independencia y la atomicidad espaciales, habiendo movilidad, la validación (commit) también cambia. Se introduce el concepto de validación dependiendo de la ubicación.
La ejecución de un fragmento, eij, satisface la validación dependiendo de la ubicación si las operaciones del fragmento terminan con una operación commit y existe un mapeo de ubicación de fragmentos (FLM, Fragment Location Mapping). De esta forma todas las operaciones del fragmento eij operan sobre réplicas espaciales definidas por un DLM (Data Location Mapping) en la ubicación identificada por un FLM. El commit es así asociado con una única ubicación L, la cual se indica con commitL.
El FLM identifica la ubicación de la ejecución de un fragmento de ejecución, que a su vez identifica la réplica espacial a ser utilizada para objetos de datos en ese fragmento. Dado el FLM que identifica la ubicación de un fragmento, el DRM (Data Region Mapping) indica la región a ser utilizada para cada objeto de datos. De esta forma tenemos un conjunto de regiones de datos asociado con cada fragmento de ejecución. Además, esto es utilizado para asegurar la consistencia espacial de los fragmentos dentro de una transacción.
En el Log
En el archivo de transacciones log, se almacenan las operaciones hechas por las transacciones antes de ser escritos en las bases de datos. El log mantiene los datos consistentes, garantizando la escritura de todos los cambios o la cancelación de éstos. Si el sistema presenta fallas inesperadas o si tiene la necesidad de reiniciar un sistema en medio de la ejecución de varias transacciones, cuando el sistema se restablezca se lleva a cabo una "recuperación automática", buscando a través de cada archivo de transacciones log la información para determinar cuáles transacciones completar, cuáles rehacer y cuáles "abortar".
En los sistemas convencionales, la generación del archivo log y su manipulación son operaciones predefinidas y fijas. En un sistema móvil la generación del log y su manejo pueden cambiar dinámicamente. En los sistemas estáticos, el manejador de recuperación (MR) está enterado de la ubicación del log. En un ambiente móvil estos mecanismos no serán válidos todo el tiempo, debido al movimiento de los fragmentos de los HM y sus constantes desconexiones. Esto hace muy complejo el proceso del logging.
Una Ti puede ser ejecutada en HMs, ESMs, HFs o en cualquiera de estos lugares. Además, si sucede que un eij, de Ti visita a más de un HM, entonces su correspondiente log se encontrará disperso en más de un HM y en más de una ESM. Esto implica que el proceso de validación (commit) pueda necesitar un mecanismo para "autentificar el log" (enlaces lógicos de todas las porciones del log), dependiendo de cómo y quien es el responsable del logging y rollback de Ti y sus eij. La consistencia y la atomicidad espacial permiten la posibilidad de realizar rollback de porciones de una transacción (a nivel de fragmentos), sin tener que deshacer todas las partes. Esto afectará la buena ubicación y el manejo del log.
A continuación se presenta una lista de opciones para la ubicación del log. Estas son ubicaciones adicionales, además de la porción del log localizado en el sitio del DBMS, donde las operaciones son ejecutadas. No se duplica el log, pero se agregan registros que reflejan el movimiento natural de la transacción. Estas opciones son solamente ubicaciones adicionales (non-DBMS) de registros log.
Asumimos que estos registros de log son almacenados, permanentemente, sólo en los sitios de la ESM, en lugar de los HM o HF. Esto facilitará la recuperación, aun cuando exista desconexión de un HM. Los registros individuales del log del DBMS continuarán residiendo en los respectivos sitios del DBMS. Kumar (1998) define diferentes posibilidades de logging y describe sus limitaciones.
Discusión
Los retos que la computación móvil ha generado, son tema de investigación en los problemas analizados en este artículo. Se han propuesto alternativas y modelos para soportar las propiedades ACID de las transacciones y los efectos de la movilidad de los dispositivos móviles. A continuación se presentan algunos enfoques y modelos propuestos, para soporte y manejo del archivo Log.
Con respecto a la ubicación del archivo Log, en los sistemas convencionales la generación del log y su manipulación son operaciones predefinidas y fijas, debido a que el manejador de recuperación (MR) está enterado de la ubicación del log. Sin embargo, en un sistema móvil la generación del log y su manejo pueden cambiar dinámicamente. Kumar (1998) ha definido diversos esquemas, partiendo del hecho de que un sistema de cómputo móvil es un sistema distribuido:1. Logging Centralizado (almacenamiento del log en un sitio designado). Bajo este esquema, un nodo que usualmente es una ESM, es designado para manejar el log. Todos los HM soportados por la ESM de todas las regiones de datos, guardarán allí sus registros de log.
Los registros de log dinámicos (generados por los HM) son manejados por una ESM estática. Como la ubicación del log es conocida y los registros de log son almacenados en un solo lugar, su manejo (acceso, borrado, etcétera) es muy sencillo. Este esquema funciona considerando lo siguiente:a) Tiene una confiabilidad muy baja. Si la ESM encargada del log falla, entonces parará todo el proceso entero del log.
En consecuencia, el procesamiento de las transacciones se afectará hasta que la ESM se recupere.b) El proceso de logging puede ocasionar "cuellos de botella", debido al tráfico en la ESM encargada del log, lo que causaría importantes retrasos.c) Para los sistemas con poca carga de trabajo y HMs con poco movimiento, este esquema provee un manejo simple y eficiente de manejo del log.2. Logging en la ESM-H. Cada HM almacena sus registros de log en su respectiva ESM-H (Estación de Soporte Móvil-Home), aunque los HM vayan cambiando alrededor del dominio geográfico y continúen teniendo acceso a los datos desde cualquier ubicación.
Todo el proceso de logging estará en la ESM-H para dicho HM. Este esquema tiene las siguientes limitaciones:a) El log entero de una Ti pudiera estar disperso en distintas ESM si los fragmentos eij de Ti son procesados por diferentes HM con diferentes ESM. Para recuperar todas las piezas de log de Ti se necesitará de un proceso de enlazamiento.b) Este esquema no funciona para datos dependientes de la ubicación. Considérese una consulta que será procesada por un HM, cuya ESM-H no es la que almacena los datos correspondientes a su ubicación. Por ejemplo, si un agente en la Ciudad de Kansas genera una consulta en su HM para obtener datos de un hotel ubicado en Dallas, el resultado podría ser incorrecto. Además, este esquema puede generar un excesivo tráfico de mensajes.3. Logging en la ESM local.
Los HMs almacenan sus registros de log en la ESM que actualmente los soporta, la cual podría ser, o no, el ESM-H donde inició la transacción. Este esquema representa el lado opuesto del esquema centralizado. Tiene las siguientes características:a) El archivo log completo de Ti quedará esparcido por todos las ESM que vaya visitando.b) Comparado con el esquema centralizado, no existe el problema de que si alguna ESM falla, todo el sistema tenga que esperar a que ésta se recupere, debido a que el log está divido por cada fragmento de ejecución de Ti. La desventaja es que se necesita mucho envío de mensajes para coordinar la validación o recuperación de Ti.Serrano-Alvarado y Roncancio (2001) y Serrano-Alvarado (2001) se han propuesto diferentes modelos de transacciones móviles, con el propósito de soportar tanto las propiedades ACID, como el manejo de la movilidad y la desconexión de los HMs:1.
Clustering es un modelo flexible, a dos niveles de consistencia, que fue introducido para tratar con las frecuentes, predecibles y variadas desconexiones. También se enfoca en mantener la consistencia de los datos, a través de todos los sitios distribuidos. El modelo está basado en la agrupación de datos relacionados semánticamente o por localidades más cercanas en forma de cluster. Los datos son almacenados o guardados en caché en el host móvil, para dar soporte a sus operaciones en forma autónoma durante las desconexiones.(Pitoura, 1995) (Pitoura, 1999)2.
El Two-tier replication, propuesto por Gray, considera tanto el enfoque transaccional, como el de replicación para ambientes móviles, donde los HMs estén ocasionalmente conectados. Existe una versión maestra de los datos y varias versiones replicadas (copias). En este modelo se soportan dos tipos de transacciones: transacciones base y tentativas. Las transacciones base son ejecutadas y tienen acceso a las versiones maestras, mientras que las transacciones tentativas se ejecutan teniendo acceso a copias replicadas de datos. Los efectos son almacenados en el HM en modo "sin conexión". Cuando la conexión se restablece, las transacciones tentativas son vueltas a ejecutar como transacciones base.(Gray, 1996)3.
Pro-Motion (P-M) es un sistema de procesamiento de transacciones móviles, orientado a la desconexión en un ambiente cliente-servidor móvil. P-M utiliza el concepto de compacts, unidades de información consistente, que encapsulan datos, métodos de acceso, información de estado y reglas de consistencia. El manejo de transacciones en P-M se lleva a cabo utilizando una combinación de los modelos de transacciones, anidadas y Transacciones Divididas, conocido como Nested-Split Transactions (NST). En P-M el sistema móvil total es una transacción muy grande y de larga duración, ejecutada en el servidor con sub-transacciones, ejecutándose en un HM, que a su vez son, cada una, la raíz de otra NST. P-M es eficiente, debido a que sólo los recursos (compacts) que sean necesitados por el HM, serán almacenados en éste. Actualmente se está desarrollando un servidor de bases de datos que soporte directamente compacts.(Moss, 1985)(Walborn, 1999)4.
Reporting considera a un ambiente de bases de datos móviles como un sistema especial de multibases de datos con requerimientos específicos, donde las transacciones en los HMs son vistas como un conjunto de sub-transacciones. Ellos proponen un modelo de transacciones abiertas-anidadas que soportan atomicidad, transacciones no-compensables y dos tipos adicionales: reporting y co-transactions. Durante su ejecución, las transacciones pueden compartir sus resultados parciales y mantener parcialmente el estado de una sub-transacción móvil (ejecutada en el HM) en la ESM.(Chrysanthis, 1993)5. Semantics-based se enfoca en el uso de objetos de información semántica, para mejorar la autonomía de un HM cuando se encuentre sin conexión. Esta contribución se concentra en la fragmentación de objetos, como una solución a operaciones concurrentes y a las limitaciones de almacenamiento del HM. Este enfoque divide grandes cantidades de datos complejos en pequeños fragmentos del mismo tipo.(Chrysanthis, 1995)6.
Prewrite intenta incrementar la disponibilidad de los datos en un HM, mediante la introducción de operaciones de pre-escritura (prewrite), además de las escrituras normales. Una pre-escritura hace que los valores sean visibles (precommit) antes de la confirmación (commit) de la transacción móvil. Las actualizaciones se hacen permanentes después por la confirmación (commit). Este modelo mantiene dos variantes de datos: prewrite y write. En prewrite se refleja el estado futuro de los datos, pero pueden existir pequeñas diferencias estructurales con los respectivos valores a confirmar. Por ejemplo, en un documento, el prewrite sería el abstract y el write vendría a ser el documento completo.(Madria, 2001)7. Con el KT (Kangaroo Transactions) se propone un modelo de transacciones móviles, que se enfoca en el movimiento del HM durante la ejecución de las transacciones. Las transacciones móviles son generadas por los HMs y son ejecutadas completamente por un "Sistema de Multibases de datos" (MDBS: Multi-database System) dentro de la red fija.
KT propone la implementación de un Agente de Acceso a Datos (Data Access Agent) dentro de Manejadores Globales de Transacciones. Este agente será ubicado en las ESM y administrará las transacciones móviles y el movimiento de los HMs.(Dunham, 1997)28. MDSTPM (Serrano-Alvarado, 2001) (Multi-Database Transactions Processing Manager architecture) propone un marco de trabajo para dar soporte a transacciones emitidas por HMs en un ambiente de multibases de datos. La contribución de este modelo se centra en la implementación de un Facilitador de Mensajes y Colas (MQF: Message and Queuing Facility) que controle el intercambio de mensajes entre el HM y el sistema de multibases de datos fijo.
El proceso es responsabilidad del DBMS local. MDSTPM coordina la ejecución de transacciones globales, planifica y coordina las validaciones de las transacciones.(Serrano-Alvarado, 2001)Una observación general es que los modelos propuestos continúan delegando la responsabilidad de preservar la consistencia de las BDs a los DBMS en la red fija. Sin embargo, las frecuentes e impredecibles desconexiones de los dispositivos móviles dan pie a que se pueda aprovechar el poder de procesamiento de algunos dispositivos, como laptops y pda's, para llevar a cabo el proceso de las transacciones del lado de los HMs, esto, en conjunto con los DBMS fijos y la creación de nuevos modelos y protocolos, que permitan aprovechar la creciente tecnología que estos dispositivos personales están experimentando.
Conclusiones: líneas de investigación prometedoras
En este artículo se presentaron las bases del procesamiento de transacciones y los modelos que han sido implementados para hacer robusto el procesamiento de transacciones móviles. Se han presentado las limitaciones del modelo tradicional y las soluciones, mediante los diferentes modelos que actualmente emplean la mayoría de los DBMS.
Los avances en tecnología de comunicaciones inalámbricas han generado nuevos problemas para soportar transacciones en tales dispositivos. Dada su movilidad, se presentan retos tales, considerando su exposición a desconexiones frecuentes, como implementar modelos que preserven las propiedades ACID de una transacción iniciada por estos dispositivos.
Las propiedades ACID de las transacciones, son actualmente responsabilidad de los DBMS en la red fija. Sin embargo, una alternativa conveniente sería permitir que dispositivos móviles, con capacidades de procesamiento, pudieran intervenir en el trabajo de preservar la consistencia e integridad de una base de datos (distribuida), es decir, que el procesamiento, monitorización, confirmación o cancelación de una transacción, sean realizados por dispositivos móviles. Delegar el control a dispositivos móviles, con capacidad de procesamiento, permitiría que el proceso de transacciones no fuera tan dependiente de la red fija. Por ejemplo, un grupo de "hombres de negocio" que se encuentren en un viaje de negocios (grupo móvil), podrían reproducir los beneficios del proceso local de servidores de bases de datos; todo esto en los dispositivos móviles, a través de enlaces inalámbricos, pero sin la necesidad de acceder a internet para llevar a cabo las transacciones.
Así, se mitigarían algunos de los problemas en computación móvil, como el tiempo de espera por el bajo ancho de banda en enlaces celulares. Asimismo, el procesamiento de las transacciones podría dividirse entre los nodos del grupo móvil que tengan el poder de procesamiento adecuado, así como dividir el resto del trabajo de las aplicaciones al resto de los dispositivos del grupo móvil.
La preservación de las propiedades ACID, puede también ser delegada a los dispositivos móviles, permitiendo a los servidores, en la red fija, realizar otro tipo de acciones, como coordinar y sincronizar el trabajo realizado por otros dispositivos, para mejorar el rendimiento en el procesamiento de transacciones móviles. El término objeto no sólo incluye objetos de almacenamiento como datos; también se refiere a objetos, tales como, ventanas, menús, etcétera, del sistema operativo y a objetos reales: impresoras, taladros, reactores, puertas, etcétera. De tal forma que una lectura implica censar su estado, mientras que una escritura implica cambiar su estado. El nombre se originó cuando Margaret Dunham se encontraba de año sabático realizando investigaciones en la Universidad de Queensland en Brisbane, Australia.
(Dunham, 1999)Bertino, E., B., Catania, A., Vinai (1998) Transactions Models and Architectures. Dipartimeno di Scienze dell'Informazione. Milano, Italy.
Chen, Y. and L. Gruenwald (1994) Research Issues for a Real-Time Nested Transaction Model, The 2nd IEEE Workshop on Real-Time Applications, July, pp. 130-135.
Chrysanthis, P. K. (1993) Synthesis of Extended Transactions Models Using ACTA. CS Technical Report 93-05, University of Pittsburgh.
Chrysanthis P. K. (1993b) Transaction Processing in Mobile Computing Environment, in Proceedings IEEE Workshop on Advances in Parallel and Distributed Systems, October, pp. 77-82.
Chrysanthis, P., K. (1995) Supporting Semantics Based Transaction Processing in Mobile Database Applications, in 14th IEEE Symposium on Reliable Distributed Systems.
Date, C. J. and White, C. J. (2001) An Introduction to Database Systems, 7a. ed., USA: Addison-Wesley.
Doucet, A., S., Gançarski, C., Leon and M., Rukoz (2000) Estrategias para verificar restricciones de integridad globales en multibase de datos con transacciones anidadas, in Proc. XXVI Conferencia Latinoamericana de Informática, CLEI'2000, Mexico City.
Dunham, M. H., A., Helal and S. Balakrishnan (1997) A Mobile Transaction Model that Captures Both the Data and Movement Behavior. ACM-Baltzer, Journal on Mobile Networks and Applications (MONET), 2 (2): 149-162, october.
Dunham, Margaret H., Vijay, Kumar (1999) Impact of Mobility on Transaction Management. International workshop on data engineering for wireless and mobile access. Pp ih-21.
Gray, Jim, Reuter, Andreus (1994) Transaction Processing: Concepts and Techniques. Morgan Kaufmann Publishers, Inc., pp. 159-235.
Gray, J. N., Helland, P., O'Neil, P. and Shasha, D. (1996) The Dangers of Replication and a Solution, in Conference on Management of Data, Canada, June, pp. 173-182.
Imielinski, T. and Badrinath, B. R. (1993) Data Management for Mobile Computing. SIGMOD Record, 22 (1):34-39, March.
Ioannisdis, John, Duchamp, Dan and Maguire, Gerald Q. Jr (1991) IP¬based Protocols for Mobile Internetworking, in Proceedings of SIGCOMM '91 Symposium, September, pp. 235--245.
Kayan, Ersan and Ulusoy, Özgür (1999) An Evaluation of Real-time Transaction Management Issues in Mobile Database Systems. Department of Computer Engineering and Information Science, Bilkent University, Bilkent, Ankara 06533, Turkey. The Computer Journal, 42 (6).
Kumar, V., Dunham, M. H. (1998) Defining Location Data Dependency, Transaction Mobility and Commitment, Technical Report 98-CSE-01, Department of Computer Science and Engineering, Southern Methodist University, February.
León, C. (2001) Transacciones Anidadas y Restricciones de Integridad. Tesis de Doctorado, Universidad Central de Venezuela.
Madria, S. K. and Bhargava, B. (2001) A Transaction Model for Improving Data Aailability in Mobile Computing. Distributed and Paralell Databases.
Moss, J. E. B. (1985) Nested Transactions: An Approach to Reliable Distributed Computing.
Cambridge: MIT Press, MA.Oracle (1992) Two-Phase Commit, 22-1-22-21.
ORACLE7 Server Concept Manual (6693-70-1292). Redwood City, CA: Oracle.
Özsu, M. T. and Valduriez, P. (1999) Principles of Distributed Database Systems. 2nd edition, USA: Prentice-Hall, Inc. pp. 381-401.
Pitoura, E., Bhargava, B. (1995) Maintaining Consistency of Data in Mobile Distributed Environments, Proceedings of the 15 th International Conference on Distributed Computing Systems, Vancouver, Canada, May 30-June 2.
Pitoura, E. and Bhargava, B. (1999) Data Consistency in Intermittently Connected Distributed Systems. Transactions on Knowledge and Data Engineering, November.
Serrano-Alvarado, Patricia, Roncancio, Claudia, Adiba, Michel (2001) Mobile Transaction Supports for DBMS. LSR-IMAG Laboratory. RR 1039-I-LSR-16, BDA'2001.
Serrano-Alvarado, Patricia, Roncancio, Claudia, Adiba, Michel (2001b) Mobile Transaction Supports for DBMS: An overview. LSR-IMAG Laboratory. Technical Report.
RR 1039-I-LSR-16, Juillet.Walborn, G. D., Chrysanthis, P. K. (1999) Transaction Processing in PRO-MOTION, Proceeding of the 1999 ACM Symposium on Applied Computing, SAC '99, San Antonio, TX, USA, pp. 389-398.
Walters, Lourens O. and Kritzinger, P. S. (2000) "Cellular Networks: Past, Present and Future" [en línea]. ACM/Crossroads, Xrds7-2. Mobile & Wireless Computing Winter 2000 Issue.
<http://www.acm.org/crossroads/xrds7-2> [Consulta: 3 septiembre 2002].
Yasemin, Ayse, SEYDIM (1999) An Overview Of Transaction Models In Mobile Environments. Department of Computer Science and Engineering, Southern Methodist University, Dallas, Technical Report 98-CSE-01. |