|
|
Selección adaptable de funciones y codificación de imágenes Palabras Clave : Codificación de imágenes, selección adaptable, diccionarios, funciones tiempo-frecuencia, "Matching Pursuit", procesamiento de imágenes.
Actualmente las técnicas de selección adaptable de funciones se han vuelto muy populares, y por esa razón se han desarrollado una gran variedad de éstas, entre las cuales se puede mencionar a las más recientes: "Matching Pursuit", "Basis Pursuit" y "High Resolution Pursuit". Los modelos de codificación de imágenes presentados en este trabajo son producto de una búsqueda de aplicaciones de las técnicas de selección adaptable, del estudio de los efectos que produce la cuantización al introducirse dentro de estas técnicas, de los métodos y modelos tradicionales de compresión y de las medidas de calidad más comunes que se emplean para la evaluación de resultados en el análisis y procesamiento de imágenes. Además, las técnicas de selección adaptable involucran algunos factores dignos de un estudio profundo, como lo son la selección del diccionario que se empleará y el criterio para detener el proceso de selección. Los modelos propuestos en este trabajo expanden una imagen a lo largo de un diccionario redundante de funciones seleccionado previamente. A partir de esta expansión, se buscan, mediante una de las técnicas de selección adaptable, como "Matching Pursuit" y "High Resolution Pursuit", los coeficientes correspondientes a las estructuras más importantes de la imagen, empleando el criterio de similitud característico de cada técnica. Se hace uso de diccionarios redundantes ya que estos diccionarios son extremadamente flexibles, sobre todo cuando se trata de obtener las correspondencias de las estructuras más importantes de una señal. A los coeficientes que se obtienen se les aplica un proceso de cuantización lineal, justo al momento de ser seleccionados, con la finalidad de evitar la propagación de errores Con los coeficientes seleccionados se tiene una "óptima" descomposición de la imagen, o bien, una nueva representación con un número reducido de elementos. Esta nueva representación corresponde a una imagen codificada con tasa de compresión alta. Los átomos seleccionados implícitamente, son representados por un conjunto de parámetros, dependiendo del modelo empleado. A estos parámetros se les ordena y aplica una técnica de compresión tradicional, para obtener una compresión efectiva de la información. Empleando un algoritmo de reconstrucción se recupera la imagen original con una alta calidad visual sujeta a evaluación. Esta evaluación se realiza empleando la escala de calidad PQS ("Picture Quality Scale") y los criterios de calidad objetiva más tradicionales.
Una señal se puede descomponer en una suma ponderada de elementos extraídos de un diccionario redundante. Estos diccionarios redundantes se han empleado en diversas aplicaciones, por ser extremadamente flexibles, sobre todo, cuando se trata de obtener las correspondencias de las estructuras más importantes de una señal. Inicialmente, S. Mallat propuso un algoritmo de selección adaptable de funciones llamado "Matching Pursuit" [Mallat1993]. Posteriormente, S. Jaggi propuso otro algoritmo llamado "High Resolution Pursuit" [Jaggi1995]. Estos algoritmos descomponen una señal en una expansión lineal de formas de onda que pertenecen a un diccionario redundante de funciones. A continuación, seleccionan algunas de las formas de onda de manera "óptima", gracias al criterio de similitud que utilizan. Esta selección la llevan a cabo de tal manera, que las formas de onda seleccionadas correspondan lo mejor posible a las estructuras de la señal en estudio. "High Resolution Pursuit" ha sido utilizado para la extracción de características y el reconocimiento de objetos, con muy buenos resultados [Jaggi1995, Jaggi1997]. Mientras, "Matching Pursuit" ha sido estudiado de manera más exhaustiva en diversas áreas del procesamiento de señales. Los modelos presentados en este artículo, son el producto de una completa investigación de las técnicas de selección adaptable de funciones, de los efectos que produce la cuantización al introducirse en estas técnicas, de los métodos tradicionales de compresión y de las medidas de calidad más comunes que se emplean para la evaluación de resultados en el análisis de imágenes. Además, las técnicas de aproximación adaptable involucran algunos factores dignos de un estudio profundo, como lo son la selección del diccionario que se empleará y el criterio para detener el proceso de selección. Los modelos propuestos expanden la imagen en estudio, a lo largo de un diccionario redundante de funciones. Este diccionario ha sido seleccionado con base en los estudios y resultados publicados, relacionados con la selección de bases óptimas. A partir de esta expansión se eligen mediante una de las técnicas de selección adaptable, los coeficientes correspondientes a las estructuras más importantes de la imagen, empleando un criterio de similitud. A los coeficientes que se obtienen se les aplica un proceso de cuantización lineal, justo al momento que son seleccionados, con la finalidad de evitar la propagación, en las iteraciones siguientes durante el proceso, del tipo de errores que se producirían si la cuantización se realizara sobre todos los coeficientes una vez obtenidos. Con los coeficientes seleccionados, se tiene una "óptima" descomposición de la imagen, con un número reducido de elementos. Esta representación corresponde a una imagen codificada, con tasa de compresión alta. Los átomos seleccionados implícitamente se representan por un conjunto de parámetros, dependiendo del modelo empleado. A estos parámetros se les aplica una técnica de compresión tradicional para obtener una compresión efectiva de la información. Empleando un algoritmo de reconstrucción, se recupera la imagen original con una alta calidad visual sujeta a evaluación. Esta evaluación se realiza empleando la escala de calidad PQS ("Picture Quality Scale") y los criterios de calidad objetiva más tradicionales, como el error cuadrático medio, la relación señal a ruido y la relación señal a ruido pico. PQS es una escala de calidad que se basa en las medidas cuantitativas de algunos factores de distorsión [Miyahara1998]. 1. Técnicas de Selección Adaptable de Funciones Recientemente las técnicas de selección adaptable se han vuelto muy populares dentro la comunidad científica encargada del estudio de señales, principalmente debido a su empleo en la búsqueda de representaciones de grandes clases de funciones. En una selección adaptable, el objetivo principal consiste en encontrar la representación de una función ¦, como una suma ponderada de elementos a partir de un diccionario redundante. Es decir, se busca que ¦ se represente de la siguiente manera: 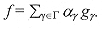 [1] [1]Donde el conjunto { gyçYÎG }corresponde a un diccionario que se extiende a lo largo del espacio de todas las posibles funciones, y que además es redundante. Detrás de una descomposición adaptable tiempo-frecuencia, está la tarea de encontrar aquellos procedimientos que puedan expandir funciones globales sobre un conjunto de formas de onda, y seleccionar algunas de estas formas de onda bajo cierto criterio a lo largo de un diccionario grande y redundante. "High Resolution Pursuit" y "Matching Pursuit" son algoritmos generales que realizan esta tarea, ya que llevan a cabo dicha descomposición y utilizan un criterio de similitud para la selección de funciones. "High Resolution Pursuit" [Jaggi1995] tiene por objeto combinar la rapidez computacional de "Matching Pursuit" [Mallat1993] y la superesolución de "Basis Pursuit" [Chen1995]. El algoritmo de "High Resolution Pursuit" es estructuralmente similar a "Matching Pursuit" y, por lo tanto, posee la misma complejidad computacional de éste. A diferencia de "Matching Pursuit", "High Resolution Pursuit" emplea una medida de similitud que resalta las correspondencias locales sobre las correspondencias globales, con lo cual es posible obtener una superesolución similar a la que exhibe "Basis Pursuit". 1.1. "Matching Pursuit" Se puede definir a un diccionario D como una familia de átomos o vectores (gy)YÎG, los cuales pertenecen al espacio de Hilbert H, y poseen una norma unitaria ç gy ç = 1. Sea V el espacio lineal cerrado del diccionario de vectores. Las expansiones lineales y finitas de los vectores en D son densas en el espacio V.Se puede decir que el diccionario está completo sí y sólo sí V = H. Para un diccionario de átomos de tiempo-frecuencia, H = L2(R), y cada uno de los vectores gy es un átomo definido por la ecuación (2). Si las expansiones lineales de los átomos de tiempo-frecuencia son densas en L2(R), entonces este diccionario está completo [Torresani1991]. 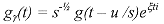 [2] [2]Sea ¦ Î H. Se desea calcular una expansión lineal de ¦ sobre un conjunto de vectores seleccionados de D, de modo que se obtenga la mejor correspondencia de su estructura interna. Esto se realiza empleando una aproximación sucesiva de ¦, con proyecciones ortogonales sobre elementos de D. Sea gy0 Î D. El vector ¦ se puede descomponer en  [3] [3]donde R¦ es el vector residual, después de aproximar ¦ en dirección de gy0. Claramente gy0 es ortogonal a R¦. Por lo tanto 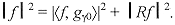 [4] [4]Para minimizar ç R ¦ ç se debe elegir gy0 Î D tal que ç á¦,gy0 ñ ç sea máximo. En algunos casos, esto se puede lograr con tan sólo encontrar un vector gg0 que sea el mejor en el sentido que cumpla con la condición 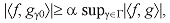 [5] [5]donde µ es un factor de optimización que satisface 0 < µ ³ 1. "Matching Pursuit" es un algoritmo iterativo que subdescompone el residuo R¦, proyectándolo sobre un vector de D, de modo que este vector corresponda lo mejor posible al residuo R¦. Este proceso se lleva a cabo de la misma manera como anteriormente se hizo para ¦. "Matching Pursuit" efectúa nuevamente este procedimiento con el siguiente residuo que se obtiene y así sucesivamente, hasta cumplir con alguna condición establecida, tal como el número de átomos a obtener o el valor de la relación ç Rn ¦ ç ¤ ç ¦ ç "Matching Pursuit" se lleva a cabo de la siguiente manera: 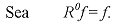
Suponiendo que se ha calculado el residuo de orden n: Rn ¦ , para n ³ 0. A continuación se escoge un elemento gy Î D , que corresponda lo mejor posible al residuo Rn ¦ , bajo la siguiente condición:  [6] [6]
donde C(Rn ¦ , gy) es una función de correlación que mide la similitud entre ¦ y gy Entonces, el residuo Rn ¦ se subdescompone en:  [7] [7]
el cual define al residuo de orden n + 1. En "Matching Pursuit", S. Mallat y Z. Zhang[1] introdujeron inicialmente la siguiente función de correlación: Se prueba entonces que el error ç Rn ¦ ê decae hacia cero. De modo que realizando iterativamente (7), se obtiene:  [8] [8]
La estructura del algoritmo de "Matching Pursuit" permite que las operaciones se efectúen rápidamente hasta cumplir con la condición que se ha establecido. 1.2. "High Resolution Pursuit" "Matching Pursuit" es un algoritmo económico, en el sentido de que en cada paso optimiza la energía que adquiere. Esto comúnmente lo lleva a escoger aquellas características que se acoplan globalmente a la estructura de la señal, sin embargo, no son las que mejor se adaptan a las estructuras locales. Para evitar este problema, S. Chen y D. Donoho introdujeron "Basis Pursuit" [Chen1995], el cual efectúa una completa optimización minimizando ågÎGçag ú sobre todas las posibles descomposiciones f = ågÎGaggg. Sin embargo, este algoritmo está casado con algunos problemas de gran escala de programación lineal, y por esta razón emplea una gran cantidad de tiempo para el cálculo. "High Resolution Pursuit" es una versión diferente a "Matching Pursuit". Emplea una función de correlación distinta, la cual permite resaltar las correspondencias locales sobre las globales, presentando la rapidez que muestra la estructura del algoritmo "Matching Pursuit". Para cada átomo de tiempo-frecuencia gy, se introduce un conjunto de índices subatómicos Iy. Iy corresponde a pequeños átomos gyi, donde yi Î Ig, con un soporte de tiempo incluido en el soporte de Ig, y modulado a la misma frecuencia. Suponiendo que el átomo gg es elegido en un seguimiento, entonces es el residuo de la señal ¦, producido en este seguimiento. Para toda gi Î Ig, áR¦, ggiñ, representa la cantidad de energía de R¦, localizada en el soporte tiempo-frecuencia de ggi. Esta cantidad debe ser menor a la energía de la señal á¦, ggiñ en la misma posición. Además, el decremento correspondiente áC(¦, gg) gg, ggiñ de la energía de la señal, no puede ser mayor a la energía de la señal misma. Esto se formaliza de la siguiente manera: 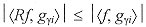 [9] [9]
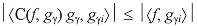 [10] [10]
A partir de estas relaciones se deriva una nueva función de correlación C(¦, gg), la cual maximiza la cantidad de la energía de la señal que el seguimiento puede adquirir cuando selecciona al átomo gg:  [11] [11]
donde e se evalúa de la siguiente manera:
Recordemos de (7) que el residuo Rn¦ se puede representar de la siguiente manera: 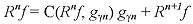 [12] [12]
donde se define al residuo de orden n + 1. En esta ocasión se emplea la función de correlación (11). Nuevamente, como el error úRn¦ê decae hacia cero, y realizando iterativamente (12) se obtiene:  [13] [13]
Esta estructura, que es la misma empleada con el algoritmo de "Matching Pursuit", permite una rápida realización de las operaciones hasta cumplir con una determinada condición. En "Matching Pursuit" el producto interno, empleado como función de correlación entre el átomo y la señal, se olvida si la señal contiene energía sobre todo el soporte tiempo-frecuencia del átomo. Por el contrario, la nueva función de correlación evita crear energía en las posiciones de tiempo donde no la hay. Debido a la nueva función de correlación, dos átomos seleccionados por la descomposición poseen un soporte de tiempo más pequeño que en la descomposición usual con "Matching Pursuit". En consecuencia, poseen un soporte con frecuencia mayor. De este modo, "High Resolution Pursuit" efectúa una descomposición tiempo-frecuencia mayor que "Matching Pursuit", aunque su resolución en frecuencia decrece. 2. Codificación de imágenes En este artículo se presentan dos modelos de codificación, debido a que los métodos de selección adaptable de funciones son muy flexibles y dan la libertad de poder elegir la manera de emplearlos. Por esta razón son muy utilizados hoy en día en diversas aplicaciones, tales como la codificación de imágenes residuales de vídeo, el análisis de señales de audio, la eliminación de ruido, el reconocimiento de formas y la detección de contornos, entre otras. En los modelos propuestos, en primer lugar se selecciona el diccionario a utilizar, el cual debe adaptarse lo mejor posible a las estructuras de la imagen para obtener buenos resultados. A continuación se expande la imagen sobre el diccionario y se inicia la selección de funciones, introduciendo una etapa intermedia de cuantización en el algoritmo. En esta etapa de cuantización se debe emplear un paso de cuantización que permita obtener buenos resultados con respecto a la tasa de compresión y la calidad de la imagen. Finalmente se desarrolla la estrategia que realice una compresión efectiva de la información obtenida, para un almacenamiento o transmisión final. 2.1 Antecedentes Las técnicas de codificación se clasifican en dos categorías: técnicas de codificación de la primera generación y técnicas de codificación de la segunda generación. Las técnicas más importantes de la primera generación utilizan bases ortonormales para representar una imagen, mientras las técnicas de la segunda generación explotan las características de la imagen y la psicofísica de la percepción visual del hombre. Actualmente existen muchos modelos de codificación de imágenes, de naturaleza muy diversa, que llegan a producir excelentes resultados, pero la gran mayoría se presentan como elementos individuales que podrían considerarse parte de un codificador completo. Un codificador completo debe integrar, además de alguna técnica de codificación, procesos de cuantización, selección, compresión efectiva y evaluación. De ahí la importancia del trabajo que aquí se presenta, en el cual, además de introducir un par de modelos de codificación, se considera e involucra los aspectos antes mencionados para que estos modelos sean lo más completos posible. Esta integridad hace que sean muy flexibles y puedan utilizarse indiscriminadamente sin importar la naturaleza de las imágenes. 2.2 Modelo de codificación por regiones Este modelo se basa en la idea presentada en los trabajos de Ralph Neff et al., relacionados con codificación de vídeo [Neff1994, Neff1995, Neff1997], donde se emplea "Matching Pursuit" para la codificación de las imágenes residuales del vídeo, y donde el primer paso consiste en la selección adecuada de un diccionario base. Esta selección se realiza empleando una técnica de entrenamiento, donde a partir de un conjunto de imágenes residuales se eligen los elementos del diccionario que mejor se adapten a las estructuras de las imágenes. Con el diccionario seleccionado, se emplea una estrategia llamada "búsqueda de la energía" para seleccionar una ventana sobre la cual se efectuará el algoritmo de selección. Esta búsqueda se realiza iterativamente, y en cada paso se obtiene un elemento del diccionario que mejor se adapte a alguna de las estructuras presentes en la ventana seleccionada. 2.2.1 El diccionario empleado El diccionario empleado con este método consiste en una colección redundante de funciones separables de Gabor 2-D. Este tipo de diccionarios es muy utilizado en el análisis de imágenes, fundamentalmente porque las funciones que lo componen, suelen adaptarse muy bien a las características principales de las imágenes. En experimentos realizados en el área de fisiología y visión, se ha observado que la respuesta en la corteza visual de animales, se aproxima a una función de Gabor al momento de aplicarle un estímulo [Bergeaud1994, Bergeaud1995]. Como se mencionó, con una técnica de entrenamiento se obtuvo al conjunto de funciones de Gabor que forman al diccionario utilizado. El conjunto empleado en este modelo se define en términos de una ventana Gaussiana: 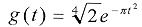 [14] [14]
Se puede entonces definir a las funciones discretas de Gabor de 1-D como un conjunto de ventanas Gaussianas escaladas: 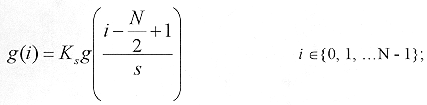 [15] [15]
Donde s es el parámetro de escala positiva. La constante Ks se elige, de modo tal que la secuencia resultante tenga norma unitaria. Si se considera que B es el conjunto de todas las escalas, podemos definir las funciones de Gabor separables de la siguiente manera: 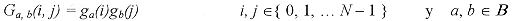 [16] [16]
En la práctica, se selecciona un conjunto finito de funciones base y se permite la existencia de todos los productos separables de estas funciones en 1-D, dentro del diccionario 2-D. Además se selecciona al conjunto de escalas diádicas s = 2j, donde j Î { 0, 1, ...,7 }. Cabe mencionar que cada función 1-D posee un tamaño asociado N, el cual permite el uso de grandes funciones. Este tamaño asociado permite tener un mejor almacenamiento e incrementa la velocidad de la búsqueda. El tamaño para cada elemento de la base 1-D se determina imponiendo un umbral de intensidad en la ventana Gaussiana g(t). Los mayores valores de escala, generalmente se trasladan a tamaños más grandes. En la Tabla 1 se muestran los tamaños asociados a cada escala. En el contexto de los seguimientos adaptables, el diccionario que se muestra en la figura1, representa una base redundante para la imagen en estudio. Para demostrar que se trata de una base redundante, basta considerar al subconjunto que contiene sólo al elemento de 1´1 pixel. Como este elemento se puede colocar en cualquier posición de la imagen, él por sí solo forma la base estándar de la imagen. Empleando las 64 formas de la Figura 1, tenemos un conjunto de bases mucho más grande. Para entender el tamaño del diccionario, se considera una imagen de 256 ´ 256 pixeles, la cual contiene 65,536 posiciones, y si en cada posición se puede colocar una de las 64 formas del diccionario, se tiene un total de 4,194,304 elementos base. 2.2.2 La búsqueda de los átomos En 2.2.1 se definieron las estructuras del diccionario 2-D, que se utilizarán para descomponer la imagen con las técnicas de selección adaptable. La aplicación directa de estas técnicas requiere de examinar cada una de las estructuras del diccionario 2-D en todas las posibles localidades de la imagen y calcular todos los valores de la medida de similitud. Para reducir esta búsqueda a un nivel más manejable, se considera la técnica empleada por Ralph Neff et al. [7, 8, 9] en la codificación de imágenes residuales. El procedimiento de la búsqueda se puede observar en la Figura 2. La imagen se divide primero en regiones. A continuación se calcula la norma de cada una de estas regiones, como se ilustra en la Figura 2(a). A este procedimiento se le llama "búsqueda de la energía". El centro del bloque con mayor valor de energía, visto en la Figura 2(b), es adoptado como un estimado inicial para la búsqueda de los valores de la medida de similitud. Enseguida, el diccionario se emplea exhaustivamente en una ventana S x S alrededor del estimado inicial, como se ve en la Figura 2(c). En la práctica, se emplean bloques de 8 ´ 8 para la búsqueda de la energía, y la ventana de búsqueda utilizada tiene un valor de S = 24 para "Matching Pursuit" y de S = 16 para "High Resolution Pursuit". Los valores de S fueron determinados con base a las pruebas realizadas durante el desarrollo del trabajo, enfatizando la velocidad de búsqueda. La búsqueda exhaustiva se puede ver de la siguiente manera. Cada estructura de tamaño N1 x N2 del diccionario, se centra en cada localidad de la ventana de búsqueda, y se calcula la medida de similitud entre la estructura y la región correspondiente de la imagen con tamaño N1 x N2. Por fortuna, parte de esta búsqueda se puede efectuar rápidamente, empleando el cálculo de productos internos separables. El valor de la mayor medida de similitud, junto con la estructura del diccionario correspondiente y la posición en la imagen, forman un conjunto de cinco parámetros, los cuales se muestran en la Tabla 2. Se puede decir que estos cinco parámetros definen un átomo, es decir, una estructura codificada dentro de la imagen. 2.2.3 Búsqueda rápida del producto interno La naturaleza separable de las estructuras del diccionario, se puede emplear para reducir la búsqueda del producto interno de manera significativa. Recordemos que en cada etapa en la cual el algoritmo encuentra un átomo, se requiere calcular el producto interno entre cada forma del diccionario 2-D y la región de la imagen correspondiente en cada localidad de la ventana de búsqueda de tamaño S x S. En el caso de "High Resolution Pursuit", además, se debe calcular el producto interno entre cada forma de onda y cada uno de los elementos de la subfamilia asociada. Considerando solamente el caso de "Matching Pursuit", para calcular el número de operaciones necesarias para encontrar un átomo, es necesario introducir primero una notación que describa las funciones base y sus tamaños asociados. Suponiendo que h y v son índices escalares en la Tabla 1 que representan los componentes 1-D de una función base separable 2-D. Específicamente, h y v son los índices que corresponden a a y b en la ecuación (16). El conjunto del diccionario puede escribirse de manera compacta como: 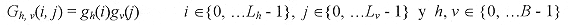 [17] [17]
donde B es el número de elementos base 1-D empleados para generar al conjunto 2-D, y Lh y Lv son los tamaños asociados a las bases de la componente horizontal y vertical, respectivamente. Suponiendo que se ignora la separabilidad. En este caso, el producto interno entre un elemento de base dado de 2-D y la región de la imagen correspondiente se puede escribir como: 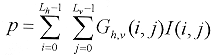 [18] [18]
El cálculo de p requiere de LhLv operaciones acumuladas de multiplicación. Para encontrar un solo átomo se requiere que el producto interno se calcule para cada una de las combinaciones de h y v en cada localidad de la ventana de búsqueda S x S. El número total de operaciones sería entonces 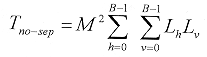 [19] [19]
Empleando los parámetros de la Tabla 1, con la ventana de búsqueda con S = 24, se tiene un total de 39, 538,944 operaciones de multiplicación acumuladas. Asumiendo un diccionario separable, el producto interno se puede escribir como: 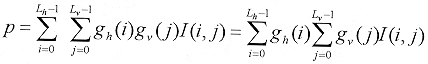 [20] [20]
El cálculo de un solo producto interno 2-D es equivalente a tomar Lh productos internos verticales 1-D, cada uno de longitud Lv, y siguiendo con un simple producto interno horizontal de longitud Lh. La búsqueda del átomo requiere calcular exhaustivamente el producto interno de cada posición, empleando todas las combinaciones de h y v . Es muy natural el calcular previamente los productos internos verticales 1-D necesarios con un gv particular, e ir de manera cíclica a través de los productos internos horizontales 1-D, empleando todas las gh posibles. Más aún, los resultados del prefiltrado vertical 1-D son aplicables también a los productos internos en las localidades adjuntas en la ventana de búsqueda. Esto motiva el uso de una "matriz de prefiltrado" grande para almacenar todos los resultados del filtrado vertical 1-D de una gv en particular. El número total de operaciones para calcular un solo átomo será: 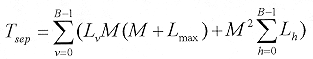 [21] [21]
Nótese que Lmax es el tamaño de la función de base 1-D más grande. Empleando los valores de la Tabla 1, se requieren 2,169,360 operaciones de multiplicación acumuladas para encontrar cada átomo. Esto produce un factor de mejoramiento en la velocidad de alrededor de 18 sobre el caso general no separable. Para el caso de "High Resolution Pursuit", a los valores obtenidos hay que multiplicarlos por un factor F, donde F representa el tamaño de la subfamilia asociada a cada átomo. Para el diccionario empleado en este trabajo, el valor de F sería en promedio cinco, con un desplazamiento de K = 2 en la escala, y siete para K = 3. 2.2.4 Etapa de cuantización Como solamente los valores de los coeficientes cuantizados estarán disponibles para la reconstrucción, el uso de valores cuantizados durante el desarrollo del algoritmo produce globalmente un error de cuantización menor con respecto a si se efectuara la cuantización al final del proceso. Así, un algoritmo de selección adaptable con cuantización, es un algoritmo en el cual cada coeficiente es cuantizado antes de obtener el siguiente residual. Recordando la manera en la cual estos algoritmos en cada iteración actualizan el residual se tiene 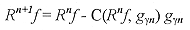 [22] [22]
Considerando que a = C(Rn¦, gyn), y definiendo la función de cuantización Q(a) = â. Se tiene ahora que 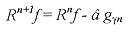 [23] [23]
Explícitamente, 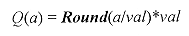 [24] [24]
Donde val es el valor del paso de cuantización y Round es la función que aproxima al entero más próximo el resultado de la operación efectuada. En este trabajo se emplea val Î { 1, 16, 32, 64 }, para el análisis de los resultados de la codificación. 2.2.5 Codificación de los parámetros Los átomos, explícitamente los cinco parámetros de cada uno de ellos, obtenidos durante el proceso de selección, son agrupados y ordenados en primer lugar de acuerdo a las estructuras que los constituyen (a, b) y a continuación, de acuerdo a su posición (x, y). Para cada par de estructuras (a, b) se conserva sólo la primera posición (x0, y0) de ésta en la imagen y las siguientes posiciones son trasladas a un parámetro relativo d, que representa el desplazamiento de dicha estructura sobre la imagen. Los valores de los coeficientes se conservan tal cual, debido a que éstos varían de acuerdo al paso de cuantización que se utilice. Por ejemplo, si se obtienen 6,000 coeficientes en el proceso, se tendrían 30,000 parámetros a codificar. Ahora bien, considerando que se tienen 64 estructuras, representadas por los 64 pares (a, b), se tendrán también 64 pares (x0, y0) de posiciones iniciales, 5,936 desplazamientos d y los 6,000 coeficientes p de los átomos, lo cual da un total de 12,188 parámetros a transmitir o almacenar, es decir, solamente el 40% del total de los parámetros obtenidos en primera instancia. Trasladando los parámetros de las estructuras y de posición obtenidos a bits, con este arreglo se reduce el número de bits necesarios para la representación de la imagen de 122,000 a sólo 12,188 bits, es decir, a un 10% del total inicial, conservándose sin cambio los coeficientes de los átomos. En la Tabla 3 se muestra la secuencia que se obtiene para almacenar los coeficientes. La secuencia resultante se codifica empleando el algoritmo universal para compresión secuencial de datos [Ziv1977]. 2.3 Modelo de codificación piramidal En este modelo, se expande la imagen empleando la transformada ondeleta 2-D. Con base en los estudios y las pruebas realizadas, se opta por el uso de ondeletas "Spline", explícitamente, ondeletas biortogonales "Spline" de reconstrucción perfecta. Principalmente porque estas funciones son una derivación de las ondeletas de Gabor, que en cuestiones de visión, por sus características, son las que mejores resultados producen. Existen diferentes tipos de funciones "Spline", por lo cual, antes de iniciar el algoritmo se obtiene una medida de costo, definida por el método adaptable de selección de bases. Esta medida de costo se utiliza para seleccionar aquella función que mejor se adapte a la imagen. A diferencia del método por regiones, en este método se efectúa una búsqueda exhaustiva a lo largo de toda la descomposición. Haciendo una similitud con el paquete de ondeletas, ésta transformada se puede considerar un paquete de ondeletas reducido, el cual contiene los elementos suficientes para efectuar una reconstrucción perfecta, por lo que no es necesario el uso de un diccionario de mayor amplitud. 2.3.1 Selección adaptable de la base Para optimizar las aproximaciones no lineales de las bases, se puede elegir de manera adaptable la base, dependiendo de las características estadísticas de la señal. Esto se efectúa minimizando una función de costos cóncava. Por ejemplo, las bases de paquetes de ondeletas y de cosenos locales son familias grandes de bases ortogonales que incluyen diferentes tipos de átomos locales de tiempo-frecuencia. La mejor base paquete de ondeletas o la mejor base coseno local, descompone la señal en átomos de tiempo-frecuencia que mejor se adaptan a las estructuras de tiempo-frecuencia de la señal. A continuación se presentan algunos ejemplos de funciones de costo. En la práctica se emplea la función de costo de entropía, la cual se eligió de manera arbitraria. Función de costo de entropía: La función de costo de entropía F(x) = -x log x es cóncava para x ³ 0. Su costo correspondiente es llamado entropía de la distribución de la energía. 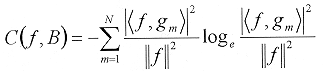 [25] [25]
Donde 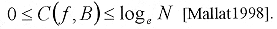 [26] [26]
Cabe hacer notar que esta entropía, a priori, no está relacionada con el número de bits requeridos para codificar los productos internos á¦, gmñ. El Teorema de Shanon muestra que la cota inferior del número de bits para codificar individualmente cada á¦, gmñ, es la entropía de la distribución de probabilidad de los valores tomados por á¦, gmñ. Esta distribución de probabilidad puede ser muy diferente a la distribución de las energías normalizadas. 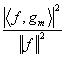
Por ejemplo, si á¦, gmñ = A para 0 £ m < N, entonces y el costo C(¦, B) = loge N es máximo. Mientras que la distribución de probabilidad del producto interno es una Dirac discreta localizada en A y su entropía es mínima e igual a cero. Función de costo Ip: Para p < 2, la función F(x) = xp/2 es cóncava para x ³ 0. El costo resultante es 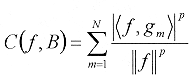 [27] [27]
Donde 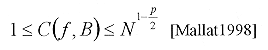
Este costo mide la norma Ip de los coeficientes de ¦ en B: 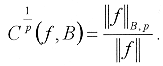
La cual se deriva de 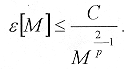
donde el error de aproximación e[M] está acotado por 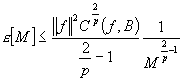
La minimización del costo Ip puede interpretarse como una reducción en el factor del decremento C tal que 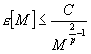
2.3.2 Búsqueda exhaustiva Una vez seleccionada la base a emplear, se realiza la expansión de la imagen, empleando la transformada ondeleta 2-D con dicha base. A continuación se inicia el algoritmo de selección adaptable de manera exhaustiva, es decir, se realiza el seguimiento o la búsqueda sobre cada uno de los coeficientes obtenidos de la expansión, los cuales para una imagen de 256 X 256 pixeles son 65,536 dispuestos en cuatro escalas. En cada paso, una vez seleccionado el coeficiente con mejor adaptación, se efectúa el proceso de cuantización de dicho coeficiente, ya que éste se empleará para actualizar la imagen residual y de esta manera se reducirá el error total en la reconstrucción a causa de dicha cuantización. Al igual que en el modelo anterior, se emplea la función de cuantización (24), con el conjunto de valores del paso de cuantización val Î { 1, 16, 32, 64 }. Cuando se emplea "Matching Pursuit", la búsqueda exhaustiva no presenta complejidad computacional alguna, ya que ésta se realiza tan sólo sobre los 65,536 coeficientes obtenidos de la descomposición, cuando estamos hablando de una imagen de 256 X 256 pixeles. Sin embargo, cuando se emplea "High Resolution Pursuit", esta búsqueda se efectúa, para la misma imagen, sobre casi cuatro millones de coeficientes, considerando un factor de desplazamiento K = 2, a lo cual se debe agregar el cálculo de los productos internos entre las subfamilias de cada coeficiente en cada iteración, teniéndose en promedio veinte millones de coeficientes, los cuales incrementan en gran medida el tiempo de búsqueda de cada átomo. Si el cálculo de productos internos entre familias se efectuara en una etapa inicial para reducir el número de cálculos en cada iteración, tal y como se realiza en el modelo por regiones, su almacenamiento requeriría de una gran cantidad de memoria, lo cual también decrementa la velocidad de búsqueda. Sin embargo, a pesar de estos inconvenientes para su uso con "High Resolution Pursuit", este modelo tiene un par de ventajas sobre el modelo de regiones. En primer lugar, necesita solamente del valor de la mayor medida de similitud o del coeficiente del átomo encontrado, junto con su posición en la imagen expandida para efectuar la reconstrucción. Estos valores forman un conjunto de tan sólo tres parámetros, los cuales se muestran en la Tabla 4, a diferencia del conjunto de cinco parámetros que se obtienen cuando se emplea el modelo por regiones. Esto implica una mejora en la tasa de compresión. Se puede decir que estos tres parámetros definen un átomo, es decir, una estructura codificada dentro de la imagen, donde la posición del coeficiente en la imagen expandida, proporciona también la información de la escala y de la frecuencia del átomo. En segundo lugar, como se observará cuando se analicen los resultados obtenidos con cada uno de los modelos propuestos, el modelo piramidal proporciona los mejores resultados, tanto en la escala de calidad PQS, como en los criterios objetivos en las imágenes reconstruidas. 2.3.3 Codificación de los parámetros En esta última etapa, para realizar una codificación efectiva, los coeficientes p de los átomos obtenidos se colocan de acuerdo a sus parámetros de posición (x, y), sobre una matriz de ceros del tamaño de la imagen, ya que las posiciones no se repiten. A esta matriz simplemente se le aplica un codificador de entropía, como es el tradicional codificador de Huffman [Huffman1952]. 3. Resultados En [Montufar1999] se realizó un estudio sobre la conveniencia del empleo tanto de "Matching Pursuit" como de "High Resolution Pursuit" para codificación de imágenes. Se emplearon tanto imágenes tradicionales (Lenna, Bárbara y Cameraman), como de microscopía electrónica (ME01 y ME02). Técnicamente, los modelos de codificación desarrollados son "Matching Pursuit Piramidal" (MPP), "Matching Pursuit Regional" (MPR) y "High Resolution Pursuit Regional" (HRPR). En la Figura 3 se muestran los resultados obtenidos para el conjunto de imágenes empleadas. Visualmente es posible observar las diferencias que se llegan a presentar cuando se emplea uno u otro modelo de codificación con una u otra imagen. Todas las imágenes poseen diferentes características entre ellas, lo cual produce diferentes resultados entre los modelos de codificación. Los modelos de codificación fueron empleados bajo las misma condiciones siempre que fue posible, esto es, un mismo diccionario, un mismo criterio de paro y un mismo paso de cuantización. Por otro lado, en la Tabla 5 se muestran los resultados comparativos de compresión entre estas técnicas y el formato estándar JPEG, como condición para tener una referencia entre los resultados obtenidos y los de un formato comercial.
En este trabajo se han presentado brevemente tres de las técnicas de aproximación adaptable más recientes: "Matching Pursuit", "Basis Pursuit" y "High Resolution Pursuit". Cada una de ellas tiene sus propias características, las cuales superan en algún aspecto a las otras. Actualmente se siguen estudiando estas técnicas, buscando mejorarlas, generar alguna nueva técnica o utilizarlas de manera óptima en alguna aplicación específica dentro del área del procesamiento de señales o imágenes Personalmente, en [Montufar1999] se utilizaron estas técnicas para la codificación de imágenes, pero su empleo no está limitado a estas tareas, ya que se puede encontrar en la literatura que su empleo se extiende, entre muchos otros, a la codificación de vídeo, detección de contornos, análisis multiresolución, reconocimiento de objetos y análisis de sonido, sin olvidar el mejoramiento de imágenes biomédicas, de radar o satélite y su desarrollo en redes neuronales, esto último, pretendiendo un procesamiento en tiempo real.
Bergeaud, F. y Mallat, S. (1994) Matching pursuit of images. Pags. 330-333. Bergeaud, F. y Mallat, S. (1995) Processing images and sound with matching pursuits. Chen, S. y Donoho, D. (1995) Basis Pursuit. Reporte Técnico. Departamento de Estadística, Universidad de Stanford. Coifman, R. R. y Wickerhauser, M. V. (1992) Entropy-based algorithms for best basis selection. Huffman, D. A. (1952) A method for the construction of minimum-redundancy codes. Proc. Jaggi, S., Carl, W. C., Mallat, S. y Willsky, A. S. (1995) High Resolution Pursuit for Feature Extraction. Reporte Técnico, MIT.. Jaggi, S. (1997) Multiscale Geometric Feature Extraction and Object Recognition. Tesis Doctoral. Mallat, S. y Zhang S . (1993) Matching Pursuits with Time-Frequency Dictionaries. Mallat, S. (1998) A wavelet tour of signal processing . Miyahara, M., Kotani, K. y Algazi, V. R. (1998) Objective picture quality scale (PQS) for image coding. Montúfar Chaveznava, R. (1999) Codificación de imágenes empleando técnicas de selección adaptable. Tesis Doctoral. DEPFI, UNAM. Neff, R., Zakhor, A. y Vetterli, M. (1994) Very low bit rate video coding using matching pursuits, Proceedings of SPIE VCIP. Pags. 47-60. Vol.2308 Neff, R. y Zakhor, A. (1995) Matching pursuit video coding at very low bit rates. IEEE Data Compression Conference, Snowbird, Utha, Neff , R. y Zakhor, A. (1997) Very low bit rate video coding based on matching pursuits. Torresani, B. . (1991) Wavelets associated with representations of the affine Wely-Heisenberg group. [Journal of Mathematical Physics]. Ziv, J. (1997) A universal algorithm for sequential data compression. [IEEE Trans. on Information Theory, IT23]. |
|
[ Este número ] |
|
|
|
Dirección General de Servicios de Cómputo
Académico-UNAM |